



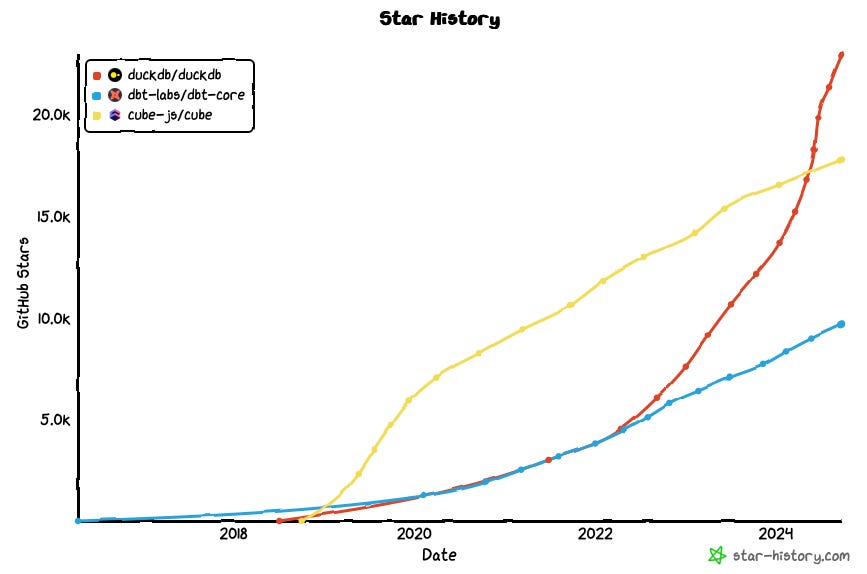

I recently helped Pete Fein with the content for his Carnegie Mellon University course on data warehouses and built the data warehouse for the course using DuckDB.

I’m really impressed by how DuckDB has progressed before and since this time, and I don’t think the main strategic reason is because:
They have great engineers
They are very focused on shipping often and well1
They are extending DuckDB repeatedly, to make it more capable than most data warehouses that have ever existed
How loved they are by the data community
DuckDB is open-source
People like ducks
People like to see Jordan Tigani in a duck suit at conferences
All of these things are true, but I think the main reason which drives some of these effects is their model of corporate structure.
Open-source DuckDB is held by DuckDB Foundation in terms of intellectual property - this foundation is not concerned directly with the monetisation of DuckDB. MotherDuck, Voltron, Posit and other contributors to the foundation are concerned with this, and have input into the features DuckDB build due to their contributions to the foundation, but the management of DuckDB is not.
This means that DuckDB can be structured very differently to your typical VC-funded company that might be trying to build a data warehouse. They don’t need go-to-market (GTM) teams like Marketing and Sales, which are expensive. Where SaaS companies build and sell software, GTM efforts and learnings massively change what product and engineering focuses on. This isn’t wrong: it’s correct for these companies to do this, they are building what their customers need and are willing to pay for. They are chasing product market fit. However, it means that these SaaS products can be skewed in shape to what pre-PMF customers asked for. Once a SaaS product gets to product-market fit (PMF), it doesn’t typically change that much, so this skew is baked into the foundations of the product.
DuckDB gets this kind of customer feedback by proxy. The contributor orgs like MotherDuck distil this information into features they want in DuckDB open-source. DuckDB effectively gets this kind of customer research for free. It’s also the best kind, because each contributor will get a limited amount of support based on their contribution amount - they are paying for these features to be built, so they are more likely to be important than where features are built on the whim of a product manager2 at a SaaS company. The contributor companies have hashed it out internally and agonised about exactly what thing they want the most, no1 and maybe 2 on their list to Duck Santa.

Then the DuckDB foundation can build these features in conjunction with what the community is asking for (dev rel is one of the few non-engineering activities DuckDB Foundation needs to run, and engineers can be good at this anyhow). Chances are that the requests by the contributors will have a decent amount of overlap with community requests.
There are many SaaS vendors who build upon an open core and offer an enhanced cloud offering on top. Many of them are meticulous about making sure their open source offering keeps up with their cloud offering, too. However, they all have to spend a huge part of their capital on GTM, which is why they have been outstripped by the DuckDB open-source project.
I think dbt-core could have been the kind of project which was looked after by a foundation and dbt Cloud could have monetised it independently. This would have allowed much more rapid improvements to dbt-core3. We’re seeing the likes of Tobiko, Quary etc come out of the woodwork because of how the pace of development in dbt-core has slowed over recent years. They wouldn’t have stood a chance if dbt-core had shipped at DuckDB speed and quality.
It feels like the only downside to this model is if DuckDB Foundation ceased to be funded and the project stalled. It’s pretty deep tech and therefore harder for any old contributor to get involved - the majority of the contributions will come from engineers paid by DuckDB Labs. However, with its momentum, I feel like the worst case scenario now is less new funding than anticipated and a freeze in hiring. This must provide the core maintainers of DuckDB with a great deal of security so they can “focus on the technical challenges as an artisanal database company”, whilst also knowing that they will be rewarded for great commercial success from DuckDB in their holdings in MotherDuck.
It reminds me of how Postgres has worked as an open-source project, now recognised as the most popular server-based OLTP database. There are many providers who monetise Postgres by offering cloud hosted offerings including all three hyperscalers and many others, too. Postgres and DuckDB have financial sponsors and Postgres has more formal code contributor organisations, too.
I wonder if we will see more providers monetising DuckDB over time and in fact all hyperscalers offering it, too. You could easily imagine a serverless offering by a hyperscaler that takes a DuckDB query to Iceberg, estimates the resources needed by the query based on table scan and memory requirements, spins up the right size instance to run the query, spins it down after the results are output. A very cheap and effective offering, that probably could replace the likes of AWS Athena for most queries.
The DuckDB Foundation provides a foundation for the future success of the DuckDB project by giving a competitive advantage in development speed, in avoiding typical SaaS GTM and Product Management work. The foundation is there to ensure open access to DuckDB in perpetuity, which instils confidence in contribution and adoption.
SaaS vendors with open-source offerings will have to make a profit one day, and this could be at the expense of open-source. This doesn’t seem possible with DuckDB and its foundation model. You might say that Apache-adopted projects operate in this way, but there are many of those that haven’t progressed, or at least not quickly. I think the DuckDB Foundation model has worked out better than the Apache model in most instances already - especially for data projects.
Can this foundation model be successfully replicated by other projects? They would have to have similar obvious utility4 to then rapidly attract contribution. DuckDB is the first time that a query engine this powerful and this easy to run has existed. In other segments, there could be room for something similar. Recently, WarpStream was acquired by Confluent - this was really bad for customer choice, but was too niche to be picked up by competition and markets authorities. If there were an open-source version of WarpStream, it could be the kind of project that might have the level of utility that would work for the foundation model.
Every time I see a release, I’m amazed at what they manage to achieve.
If this sounds derogatory, bear in mind that I am, in part, one of these people.
I know hindsight in the ZIRP rearview mirror is an easy place to make these kind of observations. With seemingly endlessly increasing VC money, no-one was particularly concerned with the viability of open-source support in SaaS companies. It’s still what I believe though.
This is why I wouldn’t really advocate the foundation model for Cube. While I believe the semantic layer does have this level of utility, it is not as obvious. We have to do education on the value of the semantic layer often, and where it’s not obvious it’s unlikely to get financial contributors to support a project foundation as easily. Therefore, the post-modern SaaS funding for open-source pattern is the best option.
Good analysis and I agree. Another way of phrasing this to consider the power of focus. The engineers working on DuckDB can dedicate all their time and creativity to making their product great. They can keep their teams lean, probably have simple communication structures, and become a super desirable place to work. You can attract the best of the best. I think the component team, feature team conversation comes into play. DuckDB is essentially a component with the limited scope and economy of scale that comes with that. By themselves, they aren't a whole solution. But when combined with other components teams, its a killer product
I struggle with DuckDBs claim to be a "Data Warehouse", it's a single process query engine. It must be combinated and integrated tightly with storage etc to call it a "Data Warehouse." Maybe MotherDuck could be called a Data Warehouse solution if they tightly couple the storage to their compute? Help me understand this. It seems like *most * DuckDB users in the wild are using it place of Pandas for example. No one, *yet*, is replacing Snowflake or Databricks completely with DuckDB yet.