
Beyond Data Modeling
Is data modeling enough?

Cube just raised a $25m funding round 🎉🧊! While I’m excited about where we’re going and what the funding unlocks, I feel the progress Cube has made as a company, long before I joined, validates that universal semantic layers are a much-needed and important segment.
I’ve been working a lot with our Sales Engineers at Cube since joining. One of the questions that they hear regularly is:
Why do we need a semantic layer? If we have a great data model built in dbt core (or otherwise), isn’t this enough to provide data access?
As you know if you’ve been reading this blog a while, this is something I’m well placed to answer!
I think there are a few aspects to this:
Consistency and governance
Interface
Security
Performance and cost
What is data modeling?
Data modeling is the process of creating a diagram that represents your data system and defines the structure, attributes, and relationships of your data entities. Data modeling organizes and simplifies your data in a way that makes it easy to understand, manage, and query, while also ensuring data integrity and consistency. Data models inform your data architecture, database design, and restructuring legacy systems.
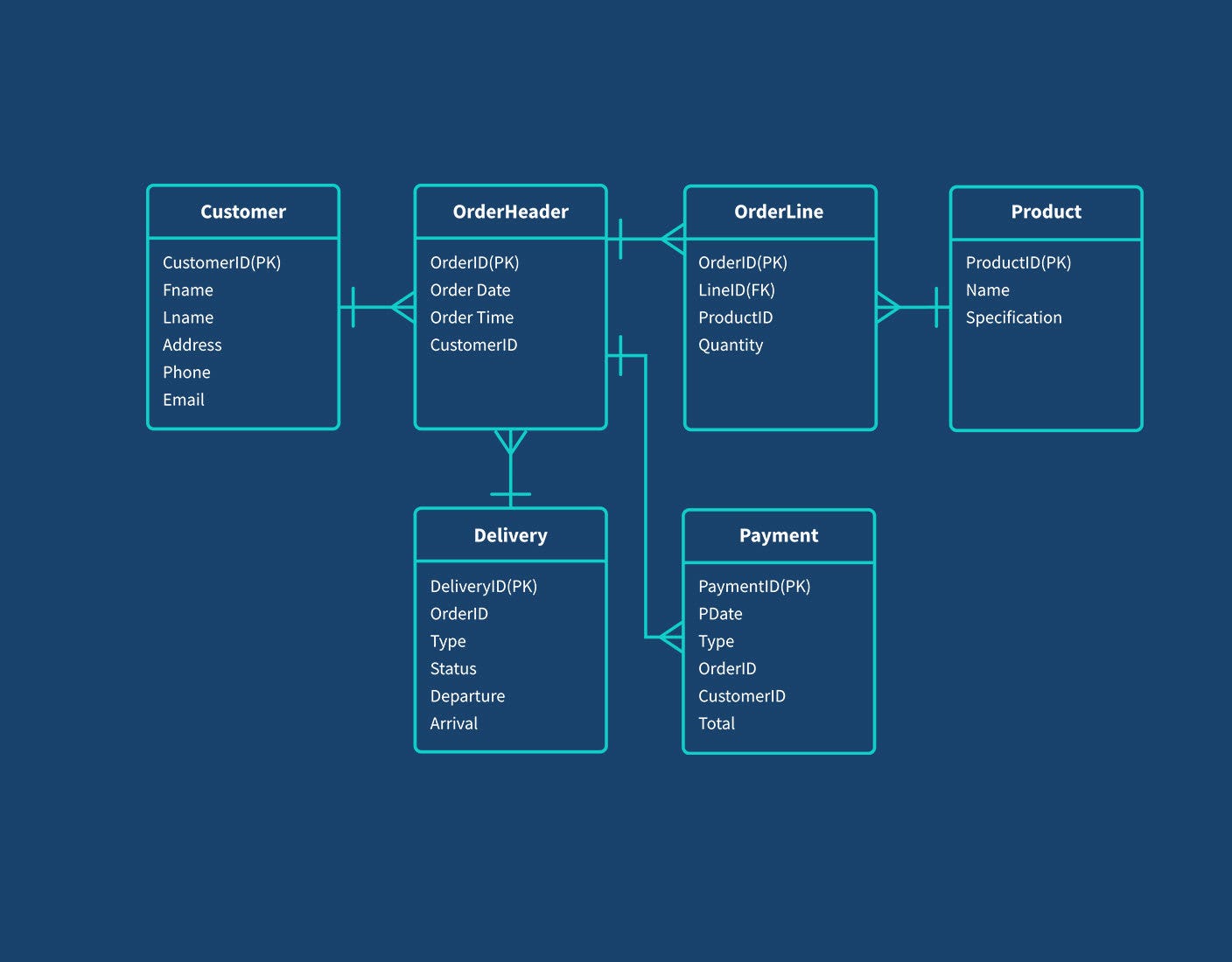
The quote here is from the Qlik link the image above is also taken from - it talks about data modeling being a visual process. I don’t feel this is necessarily true. You can easily think of it as a code-first exercise, which then generates a visual artefact instead of the other way round. However, the end result is the same and I agree with the rest of the quote.
Consistency and Governance
In the quote above, it talks about making data “easy to query”. I feel this is talking about data analysts as the people who would be doing the querying. Yes, good data modeling massively simplifies the SQL a data analyst would have to write to answer a question or produce the input for a graph/data table, but they still have to write SQL.
A data model describes how to join tables together, but this still requires an analyst to interpret the diagram and write the corresponding join, based on a request. Depending on the direction of the join for the query, a different join has to be written. For example, if you were counting the number of order lines by order month in the data model above, you might write a query like this:
select
month(order.order_date) as order_month,
count(orderline.lineid) as order_lines
from OrderHeader as order
left join OrderLines as orderline on order.orderid = orderline.orderid
group by 1
However, if you wanted to know order quantity by customer_id, you might write a query like this:
select
order.customerid as customerid,
sum(orderline.quantity) as order_quantity
from OrderLines as orderline
inner join OrderHeader as order on orderline.orderid = order.orderid
group by 1
There is intricacy in how to form the queries even on a clear, simple, well-structured data model. Care has to be taken to join the tables correctly. Care has to be taken to avoid fanouts - it would have been a very easy mistake to count(order.orderid) as orders in the first query. Not only is the analyst having to make sure they do this correctly each time they want to retrieve data, it means you do need a skilled analyst to do this retrieval each time. Someone has to write good SQL for every new retrieval without a semantic layer. Even well-drilled analysts will make mistakes from time to time or spend material time checking their work, reducing their throughput.
How metrics are calculated is implied and not explicit from the data model. Without care, it would be easy to count(orderline.lineid) as items_sold if you hadn’t noticed the quantity field or didn’t have access. The results would probably be similar enough to pass a quality check. There could also be undocumented norms like filtering records where the customer has the email address: test@test.test.
There could be nuances regarding which data is included. For example, sales from customers based in the UK could be considered part of an EU grouping before a certain date but not after. These kinds of groupings are usually dealt with using case when statements, but they’re usually not part of the data model itself. They are part of the semantics in using it, but if these aren’t codified into a semantic layer, you then rely on humans to remember to get them right or copy-paste from a template. This is slow, error-prone and hard to maintain. Where I have run data teams without semantic layers in place, having to debate whose numbers are correct and reconcile them was a regular and wasteful activity - preventing decisions being made quickly, too.
Organisations increasingly offer data products on top of their data models. These products are regularly extended and changed to meet new customer needs and wants. Having extra overhead in development time and higher risk in deployment, due to lack of consistency and governance in semantic definition, is unacceptable.
Interface and compilation
Reliable retrieval needs to be independent of being able to write SQL. If you think that a well-documented data model is a kind of knowledge graph in terms of its metadata, you can still only access it by writing SQL manually to the data warehouse, using the knowledge graph as context. All semantic layers are knowledge graphs, but not all knowledge graphs are semantic layers. It would be possible in a knowledge graph to say how to calculate any given metric, define an entity or derive a dimension on top of a data model. The key addition the semantic layer offers is the compiler and interface/s to it.
As the semantic layer can compile a more simple request into complex but consistent raw SQL, it can offer much more constrained interfaces than SQL, like a REST API. The compiler abstracts away the complexity, and risk of inconsistency, that a human writing SQL drives.
Many engineers who build customer-facing applications aren’t great at writing SQL - they are much more used to using interfaces like REST to get the data they need. Simply asking them to write raw SQL, which then has to live in their applications and services, results in slower development time and higher risk of bugs being shipped.
AI preparedness
Semantic layers provide all of the context benefits of a knowledge graph and additionally provide the constrained interface and compiler to request data and execute queries - abstracting this from the requestor. The requestor need only know what the semantic layer contains and how to ask for it in a simple format - really a list of objects and possible associated values for filtering.
My two SQL queries above could be expressed as simply as:
order lines by month, order quantity by customer
How order quantity and order lines are calculated as metrics is dealt with by the compiler. AI can select the month derived from the order date, and customerid to represent customer, from the fields available in the semantic layer.
Even wrapped in the envelope needed for an API request, and possibly split into sections… this is really simple and consistent in expression. It’s closer to language than code.
The semantic layer is critical to data intelligence and provides necessary context for AI agents to analyze data with higher accuracy. - Andrew Ferguson, VP, Databricks Ventures
I have written before about how the context and constraint of a semantic layer, with its compiler and interfaces, allows for the best possible performance for AI experiences on data:
Security
Semantic layers are in prod, people know what they contain and serve. Where they are minimal and well-defined, the entities they contain are clear and obvious. This is the best place to enforce security policies. I have written about this recently, so won’t spend long here. I’m also interested in how this relates to ABAC and will co-author a post soon in that regard.
TLDR; security policies are harder, slower and therefore more expensive and risky to maintain at the data warehouse level than at the semantic layer.
Performance and cost
The consistency of raw SQL generated by the semantic layer compiler mentioned above, means that the probability of hitting your data warehouse cache is much higher with a semantic layer, than by using a data model alone. It’s too easy for humans writing SQL on your data model to write it in slightly different ways for the same goal. Where the data warehouse cache is missed, then the query is effectively re-run at high cost and poor latency.
Semantic layers can also allow for known query patterns to be pre-aggregated into their cache at regular intervals (eg after transformation job runs), offering low latency for expected incoming queries. Their caches can also be more sophisticated than data warehouse caches, providing more functionality to increase cache hit ratio and allow for partial hits, where only additional data is pulled and added to the cached data. Cloud data warehouse vendors and providers are disincentivised to invest much in the sophistication of their caching, as it reduces their revenue, which is usually based on compute usage.
If you’ve invested the time to architect a data model, chances are it’s for an important use case you want to put into production. Oftentimes, this data model will need to be accessed with a high volume of requests that need to be served with low latency and low cost per request. Many companies now offer data to their customers as a data product in this way. Optimising cost and latency is essential here. The total cost of ownership of a semantic layer can easily be net negative when all other costs and customer experience improvements are considered.
Conclusion
Good data modeling is fundamental to delivering with data. However, with universal semantic layers available, we shouldn’t stop there. The benefits are too big to ignore.