


Come gather 'round people, wherever you roam
Coalesce 2023


This week’s post comes directly to you from San Diego, where I’m attending dbt Coalesce 2023. I’ll cover a fair amount of things announced, which I’ve tried to summarise, and I’ll keep my thoughts in italics.

Tristan’s opening remarks were about sustainability and stewardship, requiring focus on profitability and growth, as well as open source to drive standardisation. Without this, it’s very hard to have strong integrations in the modern data stack. This is why other companies using dbt-core in their products is good thing… this is standardisation of tooling. Not to be seen as others profiting from dbt Labs’ work unfairly.
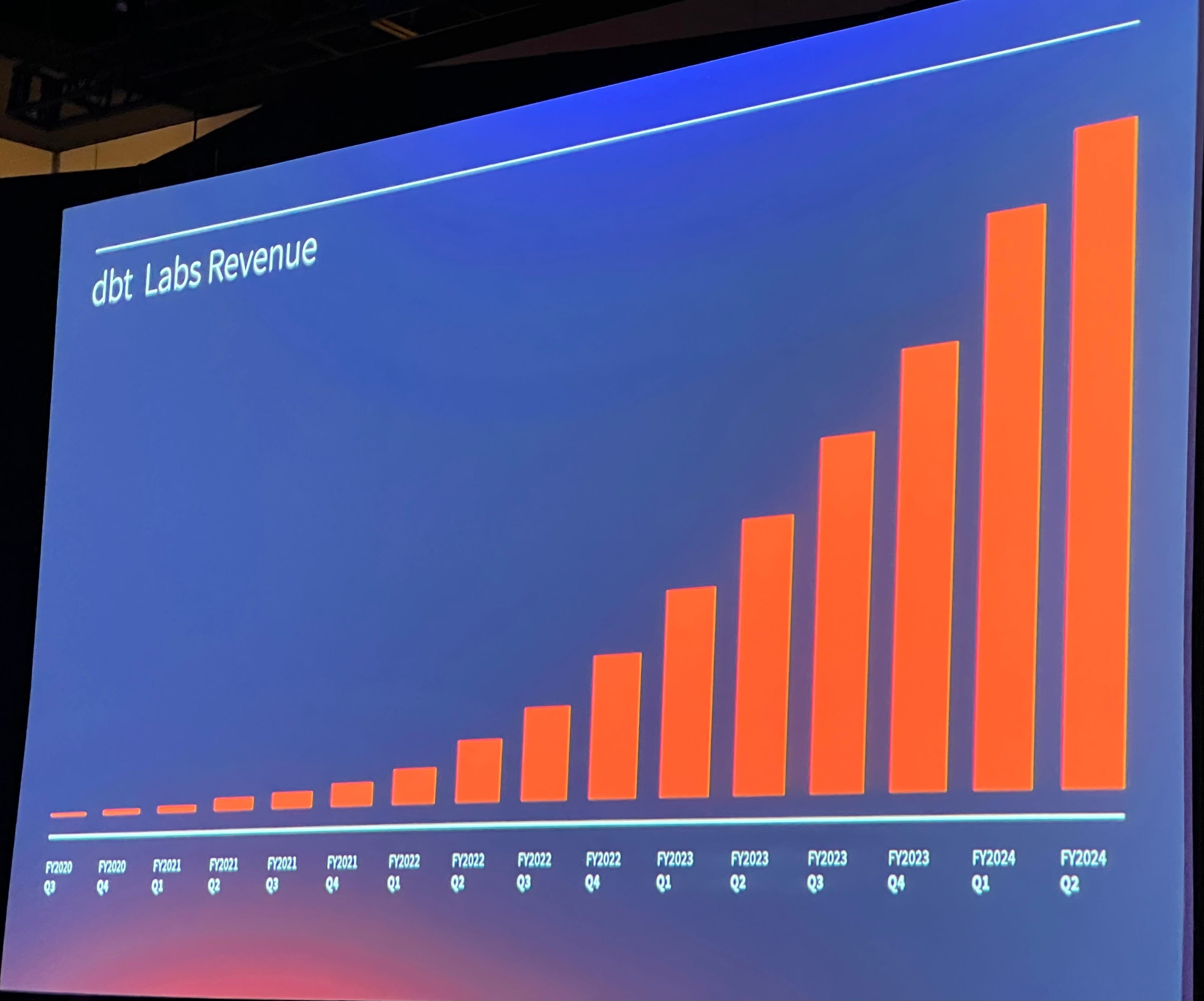
Continued commitment to Apache 2.0 for dbt-core, continued investment in dbt-core, for the benefit of all.
Cloud innovation - the best way to rent, run and operate dbt. Some problems OSS solves well and some it doesn’t. This is the reasoning behind the split between open source, cloud team and cloud enterprise features. There was some suggestion of a larger team/small enterprise plan being helpful for any orgs which didn’t quite fit on Enterprise or Team. Let’s see what happens in the pricing space over the next couple of months. We can also see that pricing for the semantic layer will be based upon queried metrics with one thousand free per month.
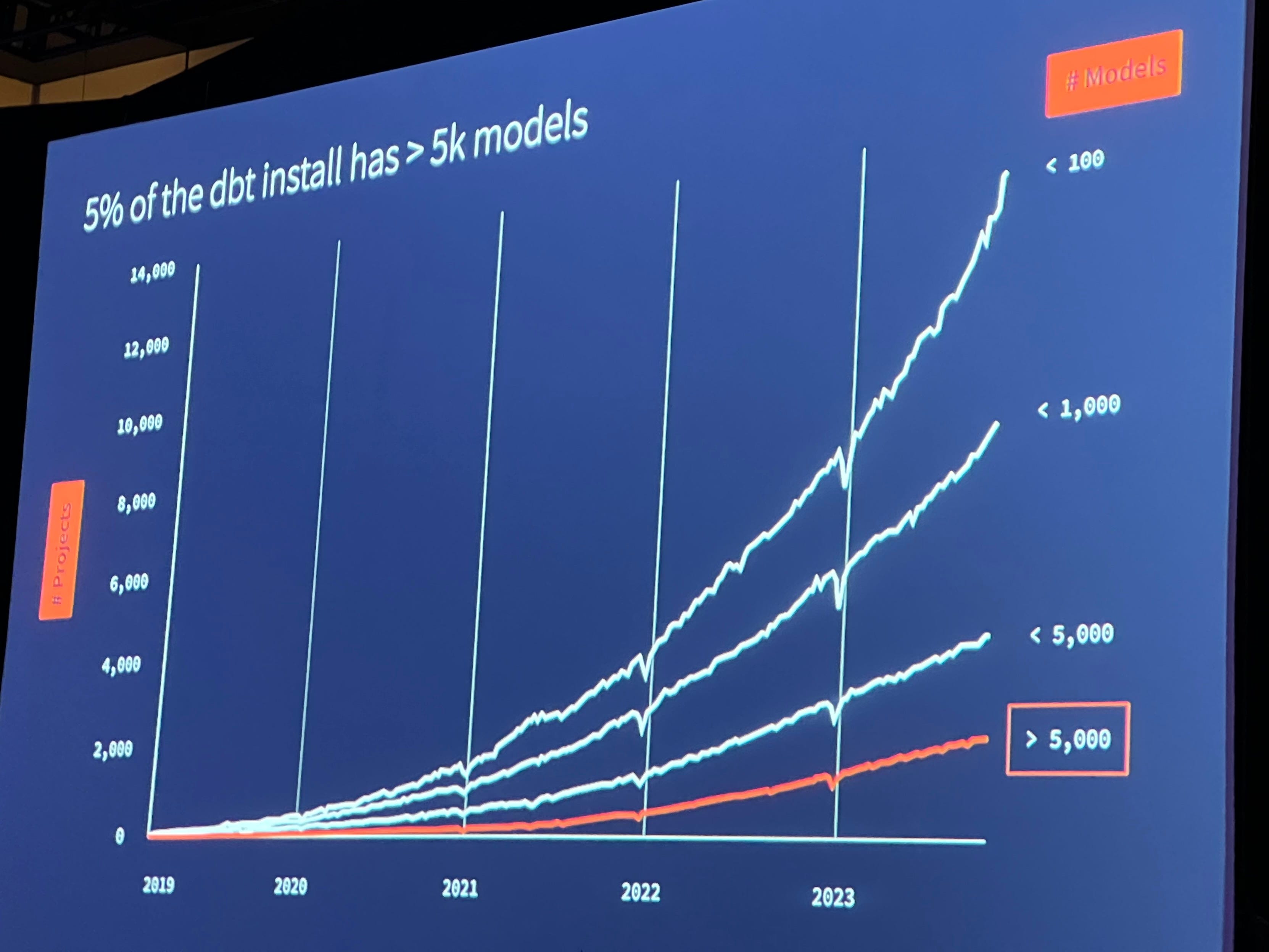
Complexity - driven by model sprawl and exponential increase in lines of code over time. This makes it hard to develop in larger projects. This being the opposite of how it felt to develop with dbt in the early days. The problem isn’t lines of code or number of models per se… it’s the resulting complexity. How do we scale, without complexity getting out of hand? Complexity reduces quality and speed and reduces user satisfaction.
The solution to this comes from stealing from SWEs, yet again... Soul of a New Machine, 70s story of how a team built a whole computer, software and hardware. Almost no collaboration, heroes didn’t scale. In the 80s and 90s, building software started to feel like working in a factory - waterfall. High failure rates, expensive. World of gantt charts. The name “Soul of a New Machine”, is very interesting in this time. Working in data did feel like this when I started my career. People in data teams didn’t really work together on anything beyond validating someone else’s process or numbers - you almost always built something alone. I’ve been one of those “heroes” in the data team - the way I made things scale was through automation and building systems to parameterise and iterate through similar work. This is why dbt made so much sense when I saw it for the first time.
The Internet forced us to build at greater speed and scale. Jeff Bezos mandated service oriented architecture, “two pizza” teams. Allows for innovation at speed, APIs instead of gantt charts. Allows small teams to operate at different speeds. What if AEs could operate in the same way as these SWE teams? With mono-repo dbt projects, you could only operate as a team of this size while your team was this size or smaller. As soon as your team was larger it began to slow down - to maintain the same level of rigour required much more work. I know senior AEs who mostly spend their time doing code review for other members of the team, the reason being that they are the ones knowledgeable enough to handle the complexity in making changes.
Every data leader wants to empower their teams to own their own data products. Small data teams working on exposing their data for other teams to safely consume, and to consume from other teams. dbt Mesh != data mesh. Some big customers have already been trialling this feature. The dbt Mesh features aim to solve the barriers to data teams operating as sets of “two pizza” teams, that can operate with speed and reduced complexity.
Focus on the DAG: serves as a good way to understand complexity. Break down the problem into smaller parts, at multiple levels. Looking at individual, team and org level:
Developer level - want to make sure you’re going through dev cycle as quickly as possible.
dbt Core
1.6 support for materialized views, retry from point of failure, model cloning
Cloud
CI/CD - separated deploy jobs from CI jobs, defer to environment vs job - doesn’t update things that don’t require it, when we detect pushes, dbt cloud stops CI jobs running on that branch.
IDE - Automated dependency management - no deps any more. SQL linting and formatting.
dbt Cloud CLI - familiar to core CLI, but with benefits of Cloud. Cloud auth, managed versions, simple installation for self-service.

dbt Cloud CLI running inside VSCode - this is a track from the new album, coming out soon
Team level - development context, ecosystem support, shared constructs
docs - operational health, failure rates etc are needed at scale. Docs need to perform at scale, too
dbt Explorer
Search resources using keywords or selectors
Lineage graph improvements with tests, exposures and metrics built in
dbt Semantic Layer
Metricflow semantic layer in GA now
Support for dynamic joins - you tell us the keys we’ll do the traversals at run time and build a semantic model on that
New complex metric types - cumulative, ratio, derived. Avoids needing to write SQL for these
Optimised SQL generation
Expanded APIs - GraphQL and Arrow
Tableau integration, where fields in workbook are simply taken from semantic layer
dbt Cloud adapter ecosystem - Azure Synapse and Fabric
Organisation level
Data mesh drivers - monolith doesn’t support all the groups of consumers
Cross project refs - can break out projects which reference each other
Contracts and interfaces - different teams using different tools of choice
Explorer lets you look at dependencies between domain projects
Contract breakage is understood in development, it tells you who is depending on this model that has a contract
Can trigger jobs to run after other jobs

Nick Handel and Roxi Pourzand’s Dune-themed semantic layer talk was fun, and informative about the why and what of semantic layers.
The new-look dbt Semantic Layer, powered by MetricFlow.
The revamped dbt semantic layer:
Define on top of dbt models
Dynamic join support, meaning keys are used for joins automatically
Create complex metrics
Integrate via robust APIs
Support for more data platforms (now including Databricks)
Optimized SQL generation
Roadmap:
Caching - Reduce redundant warehouse builds. Essential, as otherwise, similar queries will cost much more than required. I think Jordan Tigani’s talk tomorrow lunch time will describe how this should aim to work.
Exports and saved queries - Materialize metric tables in the warehouse, to bridge the gap for unsupported BI tools by providing them with pre-calculated metrics. I imagine this is a stopgap for PowerBI, which will require an MDX API to work with the semantic layer. Most other BI tools (excluding Looker) will probably look to have a rich integration, given one exists for Tableau now.
More advanced permissions/security capabilities - Govern with ease. RBAC is essential for a semantic layer, but also is more natural in a semantic layer than a data warehouse.
More integrations - Extend to more analytics tools.
Even more metric types - Handle more complex metric use cases.
I would have loved to have had the time to attend a few more of the product sessions, but I’ll catch up on these once I’m home. There are many more interesting sessions to come today and tomorrow. I’ve had a good but intense Coalesce so far - it’s been great to catch up with so many friends from the dbt community!