
Going with the Airflow - Part 2
Cobbling it together

This post is a continuation of a series on Airflow. For this second post I’ll be getting my hands dirty setting up and doing some practical learning. Hopefully, reading my experience will help others, with the same lack of skill as me, to take the plunge!
While going through the first part of my Airflow course, it felt remarkably similar to dbt, which I suppose is not a surprise at all. Ultimately, both tools do allow you to run DAGs of tasks. Unlike dbt, which uses SQL and Jinja, Airflow requires the user to write Python to define your DAGs and tasks. I can see how this will be powerful, but at the same time it's less user friendly than dbt.

vscode embedded into the Airflow course! How things have progressed in EdTech - Datacamp.com - Introduction to Airflow in Python
Looking at the Airflow web interface, it’s clear that there is a wealth of metadata available here, including information about SLA misses. It also allows you to run an ad hoc query for “simple SQL interactions with the database connections registered in Airflow.” The Logs, in conjunction with the DAGs, would be plenty of metadata for a useful integration:
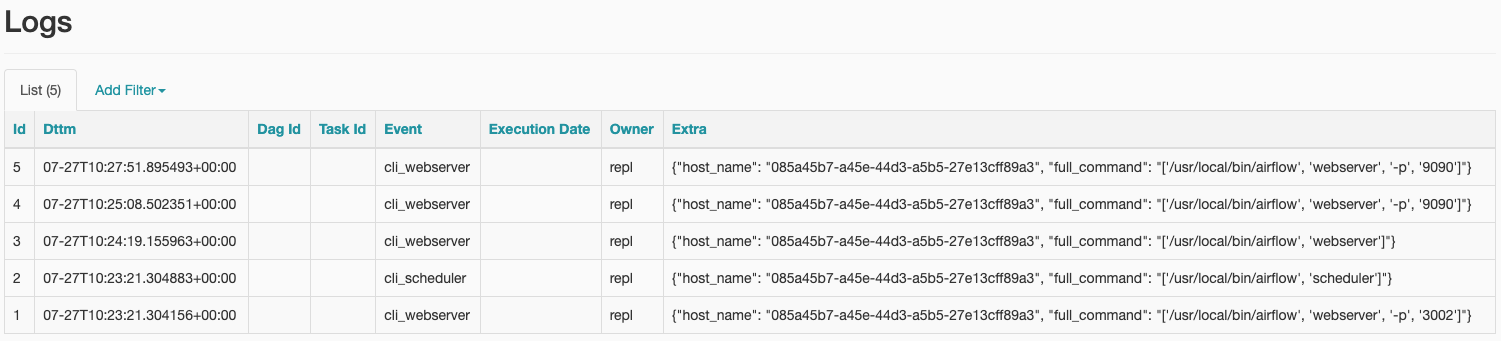

Airflow does seem much less user-friendly in many regards than dbt, even at a local operation level. There seem to be occasions when running certain commands gives you an error, but this then hangs without exiting. Although the flipside to this is that dbt never provided a web interface or scheduler as part of its open-source tooling beyond the docs. I can see how this makes it much more feasible to consider using open-source Airflow, self-hosted on its own, versus using dbt-core self-hosted on its own. With dbt-core you’d at the very least need something else to schedule its running, which is the reason why Airflow is often used for this purpose, given the interface and scheduler provided out of the box.
I think at this stage it would be worth spinning up an MWAA instance to use, as it feels like I’m about to start learning some applicable skills in the course. Here we go!

This all seems straightforward, except for the last part. I’ve never had to have a repo sync with S3 before. It triggers a bunch of questions about unknowns for me:
Should I have created a local Airflow project/repo first, even if it’s just an init?
Then, should this be synced to our github before I consider making a sync with S3?
Is there a specific folder structure that I need to adhere to?
Where do I store credentials like api keys?
It looks as though, once I have a bucket to choose, that I will then be able to choose where my DAGs are stored.
This is the sort of disconnect in tooling that is scary for someone with a Data background like mine. The elements of SWE that are the most opaque for me (and I think this is true for a lot of Data practitioners) are devops and deployment related. SWEs seem to be much more competent in this area than Data practitioners. I believe this is because they’ve had to be - they’re used to unblocking themselves and setting up different environments that they need. Data practitioners, until recently, haven’t had to be concerned with this - one advantage of the legacy stacks was that everything was enclosed in one place and many parts could just live inside your database, such as stored procedures, and scheduling was provided by an application that was bundled with the database. Data practitioners could do a lot of things using GUI interfaces or by writing database code - which they were already familiar with. The environment was already there for them to use and always online, with IT support handholding it.
This doc from AWS is not very helpful unless you have experience with CloudFormation or the AWS CLI. This is where the dbt cloud experience is much better. It guides you through everything you might need to do - it’s designed with Data practitioners in mind, who may not have the platform and cloud admin skills to set this up. Stephen more or less sums up how I feel about Airflow, so far.

“dbt has proven the value of having a semantic abstraction layer on top of modern data platforms. But it’s not enough. There’s an area of the stack yet to be addressed — one which requires knowledge of Terraform, AWS, Kubernetes, CI/CD, networking, and security principles — that also needs to be simplified and adapted to the needs of data teams. The tool data engineers need to be effective in this new world does not run scripts, it organizes systems.
So Airflow… it’s not going to work out between us. But I realize now that it’s not you, it’s me. You were built for a world I’m not interested in living in, and I think we should go ahead and move in our separate directions.”
I had another similar discussion with someone at the London Data Quality Meetup I hosted (recording here, join the Meetup group here, we’ll have a second meetup in September), they said they had tried to use Airflow but couldn’t get it to work and then tried Prefect and found it a breeze.
Let’s do some research. What is a bucket with versioning enabled? Even the description in the AWS GUI doesn’t make sense - it’s the bucket that needs to have versioning enabled, not the bucket name... right?
Let’s look up the docs. I will end up making an empty bucket and turning versioning on it this way… which seems counterintuitive. I wonder if I could find an example starter Airflow code to put in the bucket to start with. Let's have a look. This looks good, let’s download it and put it into a bucket. Thanks soggycactus!

Surely though, this repo will need to be synced with a bucket… how do you do that?
https://github.com/marketplace/actions/s3-sync
This looks like a good solution. Again, complexity that I’ll have to overcome that I haven’t had to before. Part of me wonders whether I could manage without having the repo sync with the bucket - could I just move the files when I’ve made a change? It feels like MWAA should integrate with a GitHub repository rather than you having to manage the sync yourself. Of course, AWS would probably never do this as they have their own competing product to GitHub - CodeCommit. However, I was surprised there was no option to integrate with this either… but looking at the features page for CodeCommit, I realised (what would be obvious to someone more experienced with AWS) that CodeCommit repos are S3 buckets.
It would seem logical to use CodeCommit for this repo, but I’ve never even met anyone that uses it. GitHub is more or less ubiquitous (Metaplane uses it for all repos), a few people use GitLab and Atlassian die-hards might use BitBucket.
Even doing this, I wondered about how I would have a dev environment to make changes, without doing it directly on production? This isn’t a huge concern for me, given that I’m a one person team and breaking Airflow for even a couple of days wouldn’t particularly matter, but I wonder how other teams do this?
This option allows you to effectively build a local version of your MWAA environment to develop on, but again this entails a fair bit of complexity.
Or, could I make a second MWAA environment that has a different S3 version controlled repo, which is for dev. Branching clearly won’t work, so I’d need to fork the main repo for dev, have the forked dev repo sync with a separate S3 bucket… Again, I see AWS encouraging you to use their products - I might be wrong, but I would imagine forking a repo in CodeCommit would generate a new version controlled S3 bucket for it. You could then create an MWAA instance to use with the dev bucket, and then destroy it once you’d finished with dev and your code had been merged with prod. From doing some Googling, I can’t see any mention of being able to fork a CodeCommit repo. Worst case, you could copy the S3 bucket and then use it to make the dev MWAA instance.
All of this rambling probably sounds laughably idiotic to those of you reading who have the infra expertise that I lack. At the same time, I know that I am not the least technically-competent Data practitioner out there - I’m probably middle of the road or better.
If I’m going to have to just copy S3 buckets, let’s go with the simplest solution. If, over time, we have a team of multiple people using Airflow at Metaplane and we need a better way to collaborate, we can maybe go for the GitHub to S3 sync option... or Astronomer may begin to make sense.
I’ve created the bucket with versioning - now to add the files by downloading the GitHub repo.

To get back to provisioning the MWAA instance, I’ve put in the new bucket and pointed to the DAG folder, plus requirements.txt file. Woohoo, I’m thinking I’ve done it!…But oh no, there’s a second page about:
Networking
VPC (choose or create?)
Private or Public web server access (Private stops you using public repos)
Security Groups (create new or use an existing one)
Environment Class
Encryption
Monitoring (I’ve chosen everything, given I want to see the metadata available, although I suspect the web server logs won’t be as helpful)
Airflow config options
Tags
Permissions
These are not straightforward choices for someone inexperienced in these areas! I’ve had a guess on most and where I had the choice to create new I did so, but I don’t know how someone without significant platform experience could do this.
Looks promising, let’s see if it works when I open it!
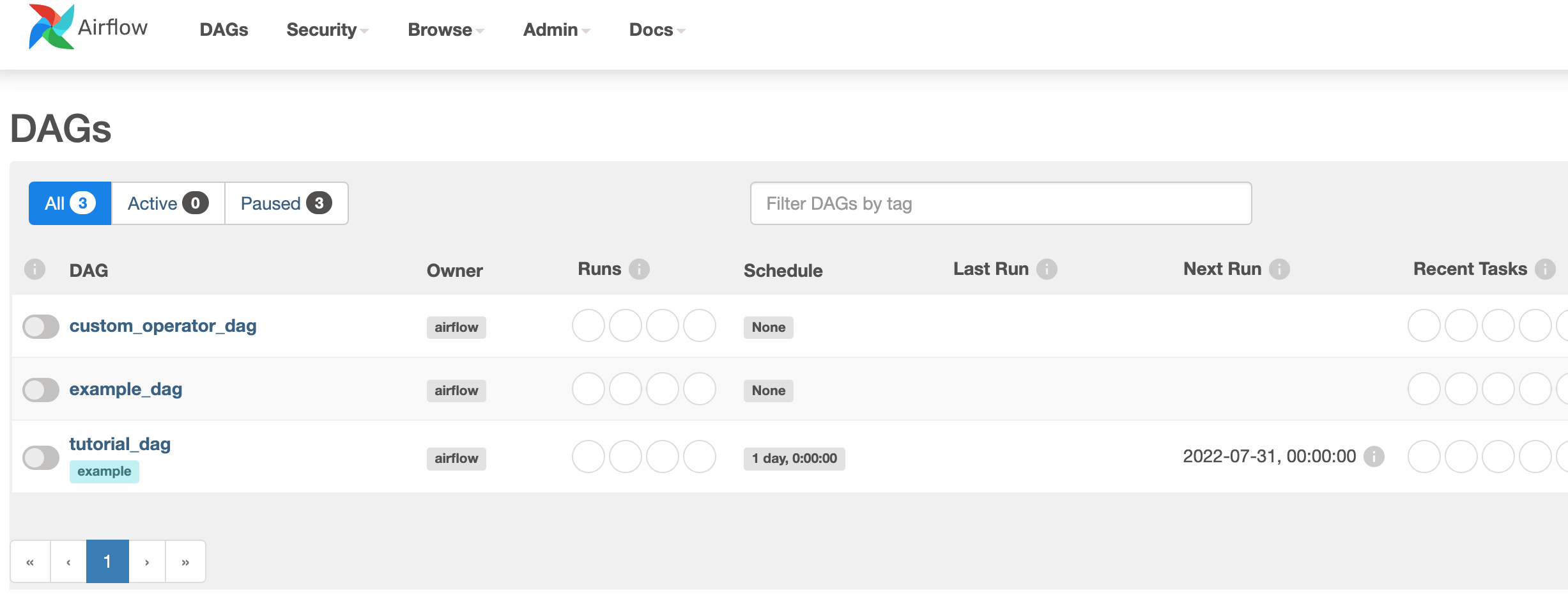
🎉 It works! At least in terms of spinning up and showing my DAGs. I’m sure it will give me some additional headaches when I start trying to build what I need to.
