
Going with the Airflow - Part 3
The birth of a DAG

There is clearly a difference between SaaS and hosted software… MWAA doesn't feel like it's a service. However, it does seem like it might cost somewhere in the region of SaaS:

$12 a day is not far off $5k a year, and that's also on the smallest instance. I imagine that if you went for a bigger instance, the costs would start to look something like those of Astronomer. I feel like this relatively high cost is due to the fact that every organisation has to run its own scheduler as part of the service. This scheduler has to be on all the time in order to check whether to run a job. A multi-tenanted scheduler would allow one scheduler to be shared by many organisations and then jobs could be run in a serverless way - much cheaper in the cloud world than running something 24/7/365. This is how I believe Dagster Cloud Serverless works, and why they can charge per minute of execution time.
Back to my Datacamp course:
Operators
These are somewhat similar to models in dbt world, except they are just tasks and don’t have to result in data materialisation (but often do). Unlike in dbt, though, dependencies have to be explicitly defined, rather than interpreted by the compiler using the ref function.

Datacamp.com - Introduction to Airflow in Python
Having to write these dependencies in this linear text-based format is inferior in my mind to using the ref function in dbt to automatically imply dependencies. When you have a branched DAG it gets complicated:

Datacamp.com - Introduction to Airflow in Python
I can see why companies using Airflow instead of dbt in the past usually didn’t have DAGs as large or as complex as those using dbt. This workflow would be very cumbersome for large DAGs that are maintained across bigger teams.
https://www.fivetran.com/blog/announcing-the-fivetran-airflow-provider
https://airflow.apache.org/docs/apache-airflow-providers-dbt-cloud/stable/operators.html
Now that I’ve completed the parts of the course around operators and dependencies, it’s probably a good time to try and build some in Metaplane’s Airflow.
The links above mention providers that could be really helpful for me, as they will give me pre-built operators (plus hooks and sensors which I haven’t learned about yet) for Fivetran and dbt cloud.
But how do you install a provider in Airflow? Strange that these docs don’t actually tell you how, but just describe what is possible. From seeing that there is a requirements.txt file, I’m guessing this is how, but it’s not that obvious to someone new to this kind of tool! I was hoping to find the equivalent of this page in the dbt docs.
Dani Sola - SVP of Data at Clark - kindly shared a link to an Airflow Provider for dbt that one of his team, plus some additional contributors, have made. I am intending to use dbt cloud, but if I were going to use dbt core, this would have been incredibly helpful - especially as it’s been well-tested with MWAA!

As a tangent, this is why I believe that we will solve the problems in the Modern Data Stack, as a community:
Not just practitioners hacking it together on their own
Not just OSS on its own
Not just SaaS Vendors
and the VC money backing them
Not just consultancies
It’s all of the above, working together, chipping away at the same problems until they’re solved. This is a whole ecosystem in its infancy - look ahead at the Software Engineering ecosystem.
Right, back on topic! The Airflow-dbt-Python provider, shared by Dani, has instructions for installation! Even with a section for MWAA! As suspected, you need to change the requirements.txt file to include the name of the provider.
From Astronomer registry, it looks as though the name of the Fivetran provider should be Airflow-provider-Fivetran and the dbt cloud one should be Apache-Airflow-providers-dbt-cloud.
It’s possible I may need to specify a version in the form of ==2.1.0 or similar, after the string for the provider name in the requirements.txt file. I assume it will either error or just always take the latest version when the instance is started, if I don’t specify.
This makes me wonder about the upgrade process for Airflow and Packages on MWAA… Would you have to destroy the instance and recreate after changing the code..? This doesn’t seem particularly graceful, or something I’d want to manage. My recollection of this with dbt cloud is that you can change the dbt version of an environment by editing it in the UI (which is good, although I know some people would like to terraform this) and by making a PR to change the package version in the dbt_requirements.yml file (which is also OK, but I’d rather all packages were managed within the environment of the UI with the dbt version, as it could then guarantee compatibility before trying to use or develop in the environment).
Anyhow, back to the Metaplane Airflow repo and a commit to put these providers in the airflow.requirements.txt file there. Upload new file to the s3 bucket with the code, done. Now I’m not entirely sure what to do… I’m hoping there will be an easy way to restart the Airflow instance and therefore, I assume, refresh the code used to run it from the bucket. Turns out, not so much… I’d have to delete my instance and create a new one. However, I tried editing it, and just by going through this it took me through the instance creation pages with what I had previously filled in.

Let’s put my kids to bed while this is going on… I’m back and it’s still not done… waiting. Yes, it’s done! My new providers are in the list, too!
I’m following the instructions to create the Fivetran connection in the Airflow Connections part of the UI, which seem fairly straightforward. Except that I am unable to click 'test' on the connection once I have entered the details. Let’s raise an issue on github.
Now, let’s try the same with dbt cloud. It looks like I need to generate a service token, but the permissions required are not detailed anywhere in this documentation… There always seems to be some guesswork involved. Let’s assume it needs job admin permissions, as would seem sensible given it’s going to run dbt jobs, but it doesn’t need to know account owner info. I need an account ID to input too… That's the integer after account/ in the dbt cloud url once I’ve signed in, but again, not much guidance in the docs. The dbt cloud docs have some useful info, but it’s quite focused on using it with Astronomer. Once again, the test button is not available in the connection manager.
I’ve just realised that setting up these connections is probably a bad idea to do at this stage, as I will probably need to restart the instance when I’ve made my DAG file. Let’s see if I definitely need to do that later.
Now, to build the DAG file with what I learned on my course. This example Fivetran dbt DAG is helpful - sensors work as I expect, so will include them now in my DAG and will learn about them in my course later. They look to check if the previous operator/s in the DAG have run. Here is my v1 DAG commit, which I assume will fail for some reason or another, given it’s the first one I’ve ever made. As expected, I need to restart the Airflow Instance for it to see my new DAG file, but it has maintained my connections!
Behold, my first Airflow DAG!
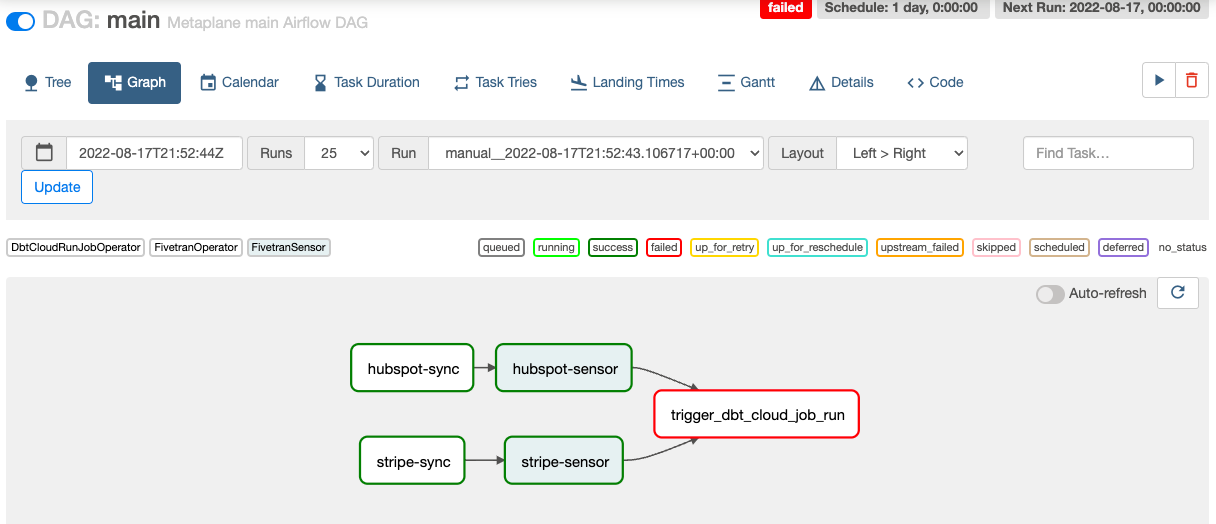
4 out 5 nodes passing on my first go isn’t too bad, and to be honest I expected the dbt cloud Operator to fail as I think I stripped out {"dbt_cloud_conn_id": "dbt_cloud", "account_id": xxxx} from my default args.
But it’s interesting to see the logs for a failure from a Metaplane product point of view, after all this is probably the log that we will want to deal with as part of an integration:

The metadata is very straightforward, it has an ID, the time of the event, the name of the DAG, the name of the node, status, execution date and owner. The only piece I feel is missing is an ID of a specific run attempt, I can see that a run_id does exist in Airflow but for some reason it’s not here.
The obvious way to understand the state of any DAG run is to find the dag_id linked to a run_id, create/parse the DAG from this to understand lineage. Then hang the node statuses from the logs of the run onto each node. It’s easy to see that only failed status nodes need alerts, as nodes skipped due to earlier failures in the DAG are consequences of these failures. They would become lineage dependencies that we would alert on.
I will debrief this experience in a later post, but thanks for bearing with me!