

Last week I published post 1 of this series, where I looked at a few other AI applications and use cases, comparing with direct use of an LLM like GPT-4:
It’s time to talk to ChatGPT - Part 1

Yes that’s right, I’ve never used ChatGPT. Yes, me, someone who founded an AI startup based on the new possibilities of LLMs like GPT3.5/4. Not kidding. Neither have I used any of the other similar tools directly, such as Claude, Mistral, etc. That’s not to say I’ve never used any AI appl…
I have been corrected, in that I’m not actually using ChatGPT and am using the API playground, but this actually is what I was aiming to do in using the LLM as directly as possible.
This week, I’m continuing with this - but first a quick GPT-4o interlude. GPT-4o was released earlier this week and promises to be twice as fast as GPT-4 Turbo, which I tried last week. So I’m going to try a side by side comparison with the LinkedIn post generation I tried last week:
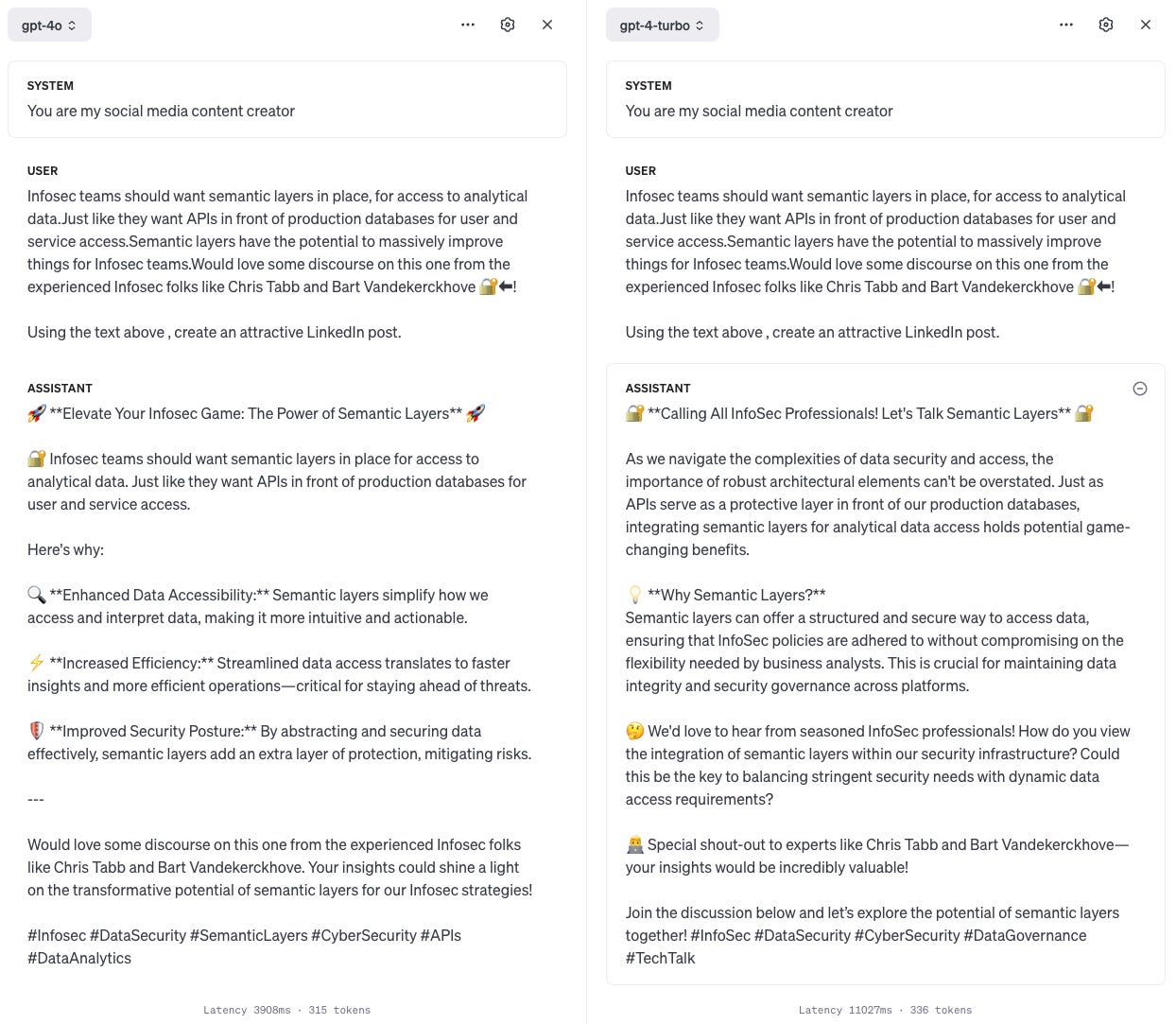
GPT-4o looks to be actually about three times faster if you can see the latency numbers in the image (3908ms vs 11027ms) and uses fewer tokens (315 vs 336). It does a decent job, but I think GPT-4 Turbo is a bit better - it explains what a semantic layer is in a better way and is a bit less generic and is elaborating from my text more.
I know the “o” stands for omni - signifying its multi-modal ability, and that I haven’t taken advantage of that here.
GPT-4 vs Notion AI
Notion AI makes your company documentation, written and stored in Notion, possible to query using natural language. It seems as though it vectorises each document to find its relevance to your question, ranks according to relevance=similarity and then feeds the top documents into the prompt with the question to get an answer. A decent RAG system.
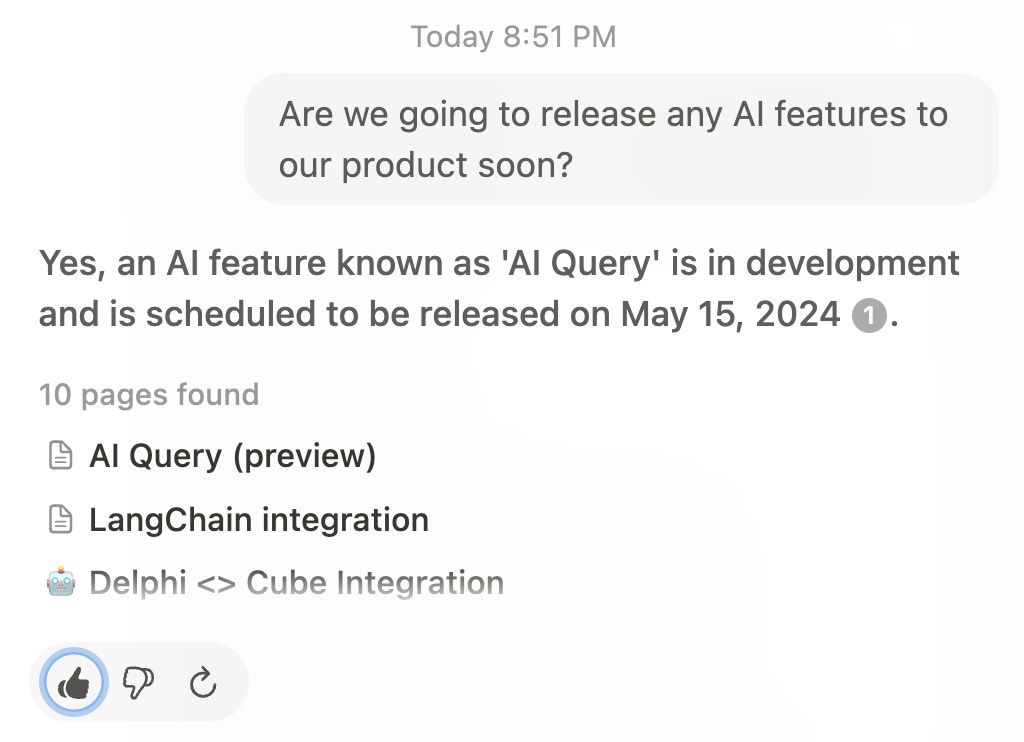
Notion AI is using the data you input into Notion as its advantage in terms of beating any other AI system that doesn’t have access to your company data. It’s not a moat as, if you were to move these docs into any other system that had a similar AI system to Notion, you could expect similar results.
I also tried getting another Notion AI feature to generate a blog post from a page. The page is an API Spec for the AI Query feature mentioned above. The vast majority of the text in the page is code showing the Request Body, a Request Example (a curl), Response Body and Response Example:
I simply opened the AI feature at the bottom of this page and asked it to generate a blog post about the content in the page:
Unleashing the Power of AI Query Generation API: A Dive into Cube Cloud
Introduction
The digital age is transforming the ways businesses analyze and interpret data. The advent of AI-powered tools has made it possible to interact with data in more intuitive ways than ever before. One such tool is Cube's AI Query Generation API. This powerful tool allows for the creation of JSON CubeQueries using natural language input, streamlining the process of data querying and making it accessible to users of various skill levels.
The AI Query Generation API
The AI Query Generation API is a unique tool that generates JSON CubeQueries from natural language inputs. This means that you can simply input your query in everyday language and the API will return a corresponding JSON CubeQuery. It offers a single shot, meaning it doesn't require a session for context elaboration or feedback to train the model. It's a minimal, efficient tool that brings the power of AI to your data analysis.
Cube Cloud AI Query Runner
In addition to the AI Query Generation API, Cube also offers the AI Query Runner. This tool leverages the AI Query Generation API to execute queries and returns the results. It's designed to work seamlessly with the API, taking the JSON CubeQuery and running it through the existing query runner that tools like Playground use. This could potentially allow for the deterministic compilation of SQL queries from the JSON CubeQuery.
UI Implementation Options
Cube offers several options for UI implementation. One option is the implementation from Catalog, where fields found from the catalog can be brought into a query playground. Another is the chat option, where users can ask catalog questions and follow-up queries in a conversational manner. For a more guided approach, Cube suggests prescriptive queries based on catalog search. Additionally, implementation can be done through an additional tab in the workspace or directly in the playground.
Conclusion
Cube's AI Query Generation API and AI Query Runner are powerful tools that can revolutionize the way businesses interact with data. By making complex data querying as simple as typing a natural language question, Cube is making data analysis more accessible and intuitive. Whether you're a data analyst needing to generate complex queries or a business user with a simple data question, Cube's API and query runner have you covered.
There is obviously no point in asking GPT-4 to write a blog post like this if it doesn’t have the API spec as context. So I pasted it into the prompt and added a line at the bottom asking it to make a blog post from the content pasted above:
Introducing AI-Enhanced Data Querying: Transform Your Analytics with Cube.dev’s New API Features
At Cube.dev, we’re always looking ahead to see how we can push the boundaries of data analytics and business intelligence. That’s why we're excited to announce significant upgrades to our Cube Cloud services, featuring the brand new AI Query Generation API and enhanced Cube Cloud AI query runner. These advanced tools are designed to make data querying much more intuitive and conversational, enabling our users to obtained actionable insights faster than ever.
What’s New: AI Query Generation API
The AI Query Generation API represents a leap forward in how you interact with your data. This API converts natural language into a JSON CubeQuery, streamlining the way you extract information from your databases. Here’s how it works:
Features of AI Query Generation API
- **Natural Language Input**: Users can now input queries in natural conversational language. This means you don't need to know specific query syntax to start pulling data.
- **JSON CubeQuery Output**: The API processes your natural language input and returns a precise JSON formatted CubeQuery, ready to fetch data.
- **Customization and Expansion Options**: Initially set for single-shot queries without session context, the AI Query Generation API is equipped to evolve. You can add custom instructions, employ Retrieval-Augmented Generation (RAG), integrate continual sessions, and enable feedback mechanisms to refine the API responses further.
Enhanced Usability through Cube Cloud AI Query Runner
Integrating seamlessly with the new AI Query Generation API is our enhanced Cube Cloud AI query runner. It takes the JSON CubeQuery and executes it via the existing query runner that powers tools like Playground. Here are some prospective UI implementations for the Cube Cloud AI query runner:
Options for UI Implementation:
- **From Catalog**: Similar to operating within a query playground, users can start with catalog-based fields and delve deeper into data exploration interactively.
- **Additional Tab in Workspace**: For a more distinct space dedicated to AI-driven queries, implementing an additional tab could be an influential approach.
- **In Playground**: Integrating directly in the existing Playground for a unified experience, easing the learning curve for our users.
Technological Synergy:
Together, the AI Query Generation API and Cube Cloud AI Query Runner can even support generating SQL by compiling the JSON CubeQuery deterministically. This ability not only enhances flexibility but also ensures that our advanced features can integrate smoothly with existing SQL-based systems.
Getting Started
Interested in integrating these new capabilities into your workflow? Here’s a quick start example using curl:
```bash
curl https://emerald-scallop.aws-us-east-1.cubecloudapp.dev/cube-api/chat \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $CUBE_TOKEN" \
-d '{
"data": [
{
"message": "top cities for sales",
"views": [
"LineItemsView"
]
}
]
}'
```
The system returns a structured response, pointing precisely to what your data query translates into in the Cube ecosystem:
```bash
{
"message": "Here's the Cube query to find the top cities by total sales.",
"cube_query": {
"measures": [
"LineItemsView.TotalAmount"
],
"dimensions": [
"LineItemsView.UsersCity"
],
"timeDimensions": [],
"order": {
"LineItemsView.TotalAmount": "desc"
}
}
}
```
What’s Next?
These updates make querying data as easy as having a conversation. Whether you are a data scientist, business analyst, or just someone curious about insights from your data, Cube.dev’s new offerings significantly reduce the complexity and time required to obtain valuable information.
We invite you to try these new features and see the difference in your data interaction and insights extraction. Stay tuned for more updates as we continue to enhance our platforms to better serve your data needs.
This is actually quite good now it has been given the context, which suggests that it is now operating at a similar level to Notion AI, given the unfair advantage has been levelled. It is wrong on a few things where the Notion AI output isn’t, but the output is similar and this one has made use of the code blocks. I’d call it a tie.
Conclusion - Notion AI’s main advantage is the information you’ve put in it, and the convenience of being able to use it in context without having to potentially paste sensitive data into a third party system.
GPT-4 vs Cursor
Whilst I think most of the other tools I’ve talked about in this series are pretty well-known, Cursor probably isn’t - Cursor is an IDE designed to provide an AI-first development experience.
I recently had to use the ACME_Insurance data model from the data.world benchmark that I’ve spoken about before. dbt Labs open-sourced it with their semantic layer code included, but I needed it in Cube format too. So I thought it would be a good candidate for trying out Cursor.
Cursor allows you to include urls which are links to docs for it to use. I inputted the dbt semantic layer docs (as you can see below) and then did the same for Cube afterwards.
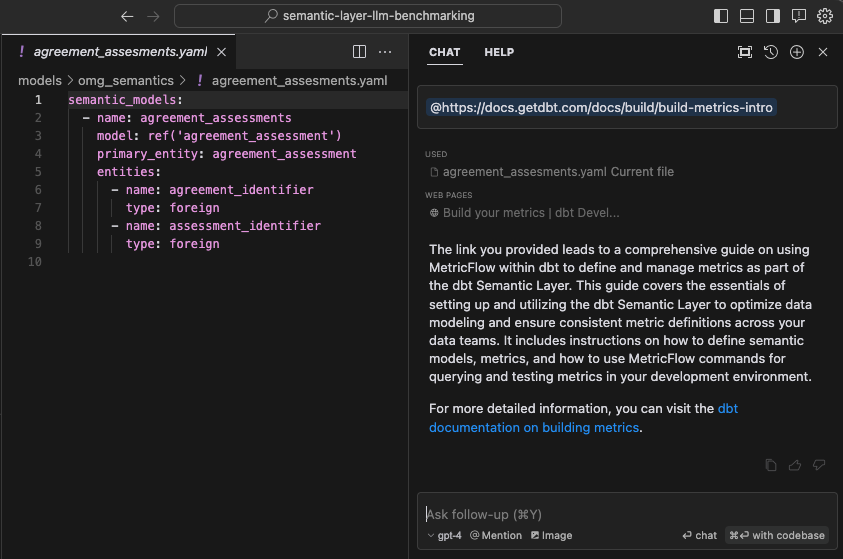
I simply asked it to convert the agreement_assessments.yaml file into Cube format:
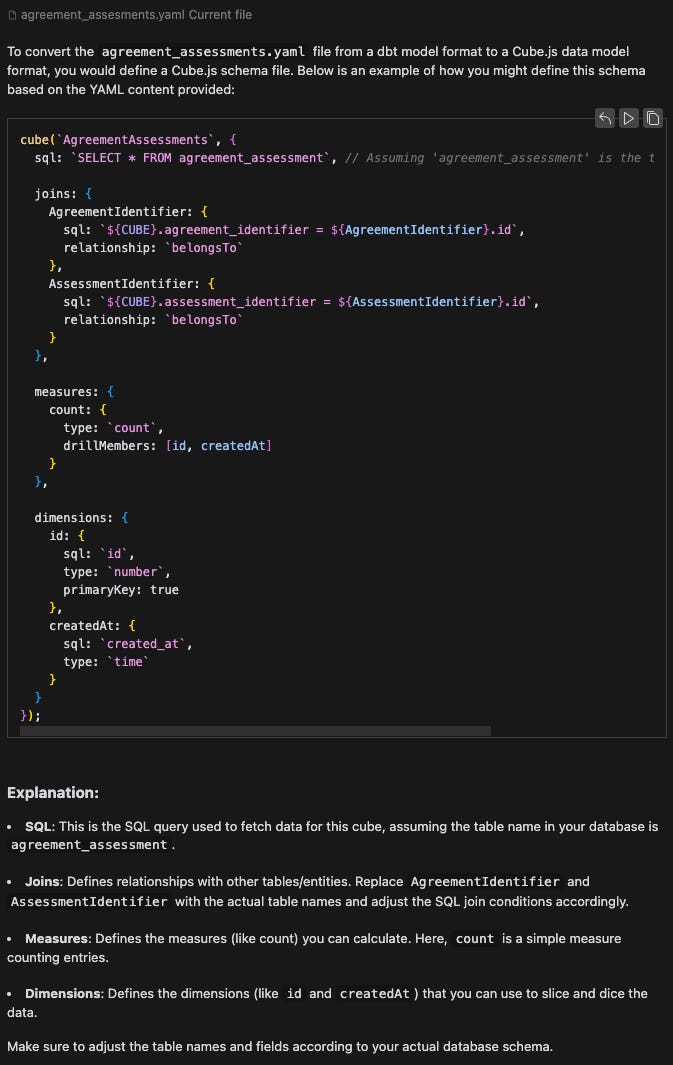
I’m really impressed - this isn’t far off. To be pedantic, I also asked it to output in Cube’s yaml format rather than the javascript format it output above. This actually causes some further issues, because in the yaml format, each object is supposed to have its name denoted as - name: rather than just being a key like in the javascript. I wonder if the LLM is more experienced with javascript than yaml too.
The other main thing I see at first look that is wrong is the relationship parameter in the joins, belongsTo is not a type of Cube join, but this is an easy fix.
It also has incorrect details of the Cubes it is joining to and their fields are wrong, but this information isn’t in the original file. If there was a way to ask it to convert a whole folder or codebase, it may not make this mistake, as it would have the context of the other files that exist.

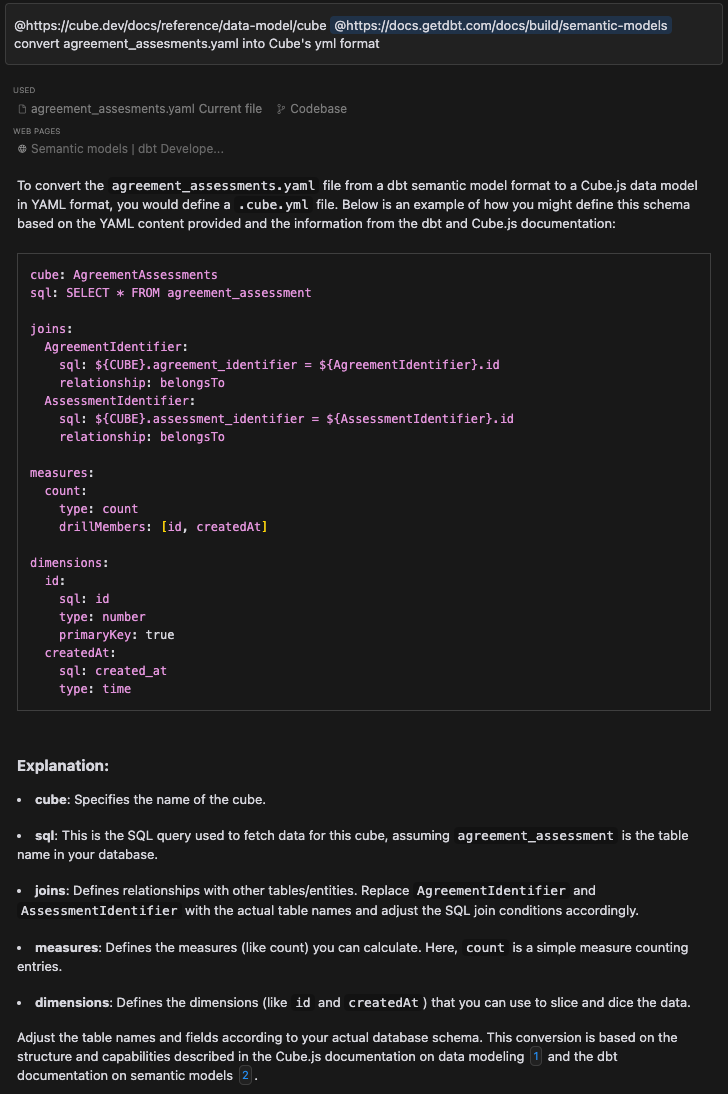
This isn’t quite as good as what Cursor achieved but it is not far off, which you may expect given Cursor was using GPT-4 anyhow. GPT-4 doesn’t allow fine-tuning so Cursor is using RAG, prompt-engineering or likely both to enhance the performance of GPT-4 and also to reduce what the user needs to input.
Cursor can afford to use the most powerful and expensive model available for this kind of use case, as the volume of requests will be relatively low.
The main advantage with Cursor, though, is that it’s much more convenient. I only had to say “convert agreement_assessments.yaml into Cube format” as my message there. I also gave it the current docs for dbt and Cube semantic layers. So it had current code formats which may not be the case for GPT-4o here which has data up to October 2023 and may have been pre-trained on older format data if it was on stack overflow etc from previous years. It’s not really possible for me to give GPT-4 a url with docs to read.
I used Cursor’s chat functionality, as you can give it remote docs there, but I could also have done this in-line with the code like using a typical IDE copilot.
Cursor is the winner here, but I actually feel its advantage is somewhat fragile. Given how well GPT-4o did with basic prompting, another company could easily match or improve on Cursor’s output. I think it could have done more to ensure the output is correct, from the context of the Cube docs.
GPT-4 vs AI data applications
Now with Snowflake Copilot, Delphi, Cube AI API… it’s really hard to even get GPT-4 to manually output something similar. The context is huge and structuring it into a prompt GUI window is impractical. In addition to that, it’s not feasible for me to do RAG manually and to do it as well as a RAG system. Even with some of the easier Snowflake queries I generated using their copilot, I would have had to find the relevant database schema parts, feed them into the prompt in a way the LLM could handle, feed in the Snowflake docs to show it how to generate Snowflake-specific SQL, then the question… This is too much work to bother with as someone who can write the SQL themselves. It also requires too much knowledge from someone non-technical.
I think this shows a clear boundary in where you can use ChatGPT on its own vs where you would definitely want an application.
Am I being too functional in my use? Am I missing the magic? Maybe… but to me it’s a tool to be used for a purpose. I don’t want to “chat” with it, I want to get it to do something of value.
In general, I prefer the LLM applications I’m used to over direct use of GPT-4. They are:
Convenient in having the AI assistance exactly where I want to use it with the right context (eg Cursor).
Use the data I have input into the application to perform better (Superhuman/Notion).
Are sufficiently complex to make manual prompting impractical (Snowflake Copilot, Delphi, Cube AI API).
They can all do the thing they were built to do quite well (barring LinkedIn - but they haven’t really tried, have they?). GPT-4 does reasonably well on its own, where it has been pre-trained on the required data, but is useless if this isn’t true and it isn’t provided. It shows how much value can be added with RAG systems, vector search, prompt engineering and constraint through methods like text-to-SL.
Databases are very useful and valuable foundational tech, but the applications built around them are orders of magnitude more valuable in aggregate. I believe the same will be true of LLMs and LLM applications.