


Same Slack, Different Day
...starting remote as a Data professional

Can you remember your last first day at a new company? For many of us it would have been in person, and you may recall your orientation and saying hi to a hundred people and immediately forgetting their names. You would however, probably learn the names and roles of people who worked close to your desk and in your team.

Starting remote is a different story: you will (hopefully) be given a list of key people to speak to, as you will be working with them closely in your role. You may also decide who else you might like to speak to in the company org chart or HR platform. This early network is very different to the one from the in person pre-2020 experience. It’s much more focused on your delivery rather than your proximity to others. In fact, it’s entirely likely that you may never speak to someone at your new remote company, whereas in person you would have met someone in person in the kitchen or some other common area.
This network in a remote company is cross-functional from the outset and then fills in the gaps as needed, whereas in person it’s discipline specific to start with and then gradually expands to other relevant areas over time. I think this makes it much less likely to have silos in remote as sometimes, with in person, the gradual expansion to other disciplines and domains doesn’t happen or at least not enough.
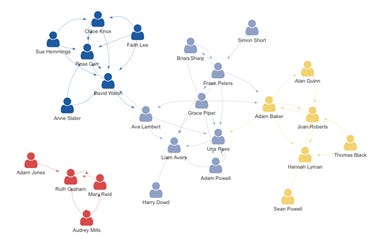
In my first two weeks at Ruby Labs, I have worked with Product Managers, Finance, HR and Talent, Engineers, Marketing as well as my Data team and the Senior Leadership Team of which I am part. This level of cross-functional collaboration would have probably taken much longer in person.
However, one thing which has been more difficult, but anticipated to be so, has been learning more about my specific domain of Data. As Ruby Labs is a pretty young company and most of the data team have been hired recently, there hasn’t been the time spent on discoverability and documentation of data assets that is present at a company with a more mature data org. When you have a transform and metrics layer in place, the code you have written becomes documentation in itself and allows your data to become more discoverable; not only in content but composition and lineage too.

There are some jobs built in Airflow (Composer) which allow you to see the shape of some data pipelines, but there is a large gap from there to the metrics the company looks at. This gap is filled by long SQL scripts with transactions and temp tables, which are hard and slow to work with and even worse to debug. In this state, which was the starting point at every org I have ever worked with, turning around basic metrics is incredibly slow. These metrics are often initially wrong and then debugging takes just as long again. It leaves stakeholders believing the data team is incompetent: not only are these stakeholders starved of data they can’t get themselves, the data they get is usually wrong to start with.
What would “good” look like for a new data person joining an org? I think there are a few different focuses to this: discoverability, trustworthiness, dataOps and lineage.
Discoverability
An understanding of what data exists about domains, what its grain is, what events or entities does it relate to. What do the columns or fields mean, what properties do they have, such as uniqueness, contain nulls, distribution etc. Although this crosses over into lineage too, it’s good to understand what data is used to calculate specific metrics.
Lineage
This is the org wide DAG of data: what data is used to make what other data and so on, until it reaches an analytical or reverse ETL endpoint. Field and column level lineage would be even better and is increasingly supported in tools.

Trustworthiness
When you come into a business it’s hard to know what data is trusted, even if something is used heavily… is it actually trusted by its users? Do they think it’s correct? Does it match other sources?

DataOps
Often trustworthiness gets degraded because of temporary but possibly regular data issues, job failures etc which mean when key stakeholders look at data in the morning, they are almost expecting it to be wrong because of how often that has been the case. Understanding this operational level of quality isn’t necessary from the get go but is useful soon after as it is metadata about trustworthiness.
We can’t just expect to spin our chair round and tap someone on the shoulder to ask for this metadata from a colleague; it was never a scalable solution to begin with. These questions and answers are too valuable to be asked over and over again without automatically becoming documentation for the next person to access. It has often been the case that you would get two slightly different answers from two experienced colleagues - if it’s codified then the differences can be addressed with consistency or divergence understood.
Wherever this metadata lives, it needs to be interactive and what you might call a “living document”, probably with a way for questions can be asked about data with answers by domain owners. These answers should also be able to be deprecated or removed as systems change over time. Imagine a situation where you had a legacy system and a new one; the questions answered about the legacy system remain valid metadata forever once the system is taken down, and all that remains is the data, which has been moved to the new system. This data from the old system still needs to be understood, so it can be successfully blended with data from the new system by analytics and data engineers. This metadata should also end up in version-controlled storage that is independent from the tool with the user interface, which is likely to be proprietary.
It’s currently easier, in many circumstances, to onboard as a software engineer because of how ubiquitous git is and how the devops toolchain (terraform, containerisation/kubernetes, standardised monitoring, CI/CD) is improving developer experience. Not to mention how software engineers inherently have higher technical capability than other staff and a very focused scope in which they operate. The end goal should be that, with stewardship of this metadata and strong DataOps processes, it should be comparably easy to onboard a data professional as any other and at least as easily as with a software engineer.