
Semantic Superiority - Part 3
State of the Join

In last week’s post, which is the second part of this series, I covered governance, security, accessibility and developer experience benefits generated by semantic layers, plus the difference between semantic and metrics layers:

This week I want to look at the semantic layers available, in what form, and some of their pros and cons.
Firstly, I think it’s worth talking about where these semantic layers are positioned. In the past, they have typically been part of BI tools: Business Objects, Microstrategy, Power BI (MDX), Looker (LookML), Thoughtspot, Veezoo, Lightdash and Metabase are the most well-known examples. I know that the latter five require you to set up a semantic layer to function - all selectable dimensions and metrics in them must also be in the semantic layer. This is actually a good thing, as otherwise you’ll have a great deal of work in your BI tool that runs off custom SQL queries, and the benefits of having a semantic layer are wiped out.
A huge number of organisations use these tools and there are some BI tools notably missing from the list which are very widespread, but don’t have a semantic layer available, even if they have acquired them in the past.
There are pros and cons to a semantic layer being in a BI tool:
Pros:
BI tools have budgets and established value to organisations - if it’s bundled with the BI tool, then you don’t have to have another vendor and another spend to justify.
BI tools give an immediate use case for a semantic layer to be valuable.
Until the last decade, BI tools were pretty much the sole consumption point for data. There wasn’t any need for a semantic layer to be separate if it was only there to serve the BI tool. If your organisation still operates this way, then you may be adding unneeded complexity by having a separate semantic layer.
If the BI tool bundles the semantic layer, you can expect the two to be compatible with each other. This integration then isn’t yet another thing to have to manage for the data team.
It’s easier to have CI/CD processes and dev tooling that tells you when semantic layer changes break downstream BI objects. Standalone semantic layers would need to be informed that downstream BI objects depended on their assets, and a means of testing whether changes in the semantic layer would break downstream BI objects in another system would need to exist - this isn’t easy 😅 and requires cooperation that may not be possible.
Cons:
Lock-in, lock-in, lock-in… did I say lock-in? I’ve written about this at great length before and it seems some people were listening 😄. This problem alone is reason enough not to choose a semantics layer built-in to a BI tool. Until relatively recently though, there weren’t any other choices, so good data folks took the option they had.
A semantic layer built into a BI tool will optimise to the features the BI tool offers. It is unlikely to be the best implementation of a semantic layer. For example, the concept of explores in LookML is there to fit navigation in Looker rather than serving a clear purpose in a semantic layer, as a true entity type would.
Cost - as we know, bundling is a way to deliver additional value to customers: you can often sell products for more if they are bundled than if the individual products were purchased separately. Cost of Looker > Cost of Cube + Cost of Preset. Cost of Thoughtspot > Cost of dbt Cloud + Cost of Mode.
A standalone semantic layer can serve many use cases, not just BI - embedded analytics, operations, niche backend… to name a few.
It makes more sense from a developer experience point of view for a semantic layer to be defined near or adjacent to where data modelling is defined. The two activities are so closely linked, with skillsets very closely aligned, too. If the downstream assets like dashboards/exports/APIs were then also defined in the same place, detection of where changes break downstream assets would be greatly enhanced and issues made more transparent.
I don’t want to spend a lot of time comparing the built-in semantic layers - as you can tell, I feel standalone is the future:
Looker
SaaS.
LookML is currently locked into the platform.
AND looks likely to be replaced by Looker Modeller in the medium to long term.
This is a metrics layer, as it doesn’t have true entities - it was probably intended that explores should be entities, but the structure isn’t there to encourage or enforce this.
I would avoid going with this for now and, if you’re already on it, you should talk to your GCP rep about being migrated to Looker Modeller from LookML, which should give you a fair bit of freedom.
Expensive.
Has APIs for using the metrics layer elsewhere.
Thoughtspot
SaaS.
TML is locked into the platform.
Similar to Looker, it is a metrics layer, as it doesn’t have true entities.
Most expensive BI tool out there - charging is now on per query basis, even though there is no real unit economics alignment.
If you have the budget and don’t have any other need of a semantic layer than BI and are sure you never will - this could be a good choice.
They have announced support for dbt metrics too, although this is still early but a good indication that there is commitment to reducing lock-in.
Has APIs for using the metrics layer elsewhere.
Veezoo
SaaS.
VKL is locked into the platform.
Veezoo has a true semantic layer, with an explicit and extensible way to express entities.
As they are a younger company than the two SaaS offerings above, their pricing is much more affordable. However, they have some big name early customers showing early ability to deal with enterprise requirements.
As their semantic layer is probably one of the most advanced on the market and perfectly suited to their user interface, they are unlikely to support a standalone semantic layer until it has feature parity with theirs.
No APIs for use with other tooling, although this is probably something on the roadmap, rather than an intentional lack of support.
Metabase
Open-source, with cloud version.
Modelling is locked into the software.
Metrics layer, as it has no true entities and it looks like relationships have to be defined in the GUI. I think Metabase is probably the weakest of the five here. It would really make sense for them to directly support a standalone semantic layer like dbt/MetricFlow or Cube.
Has APIs for using the metrics layer elsewhere.
Open-source, with cloud version.
Has own lightweight metrics layer that exists in dbt schema.yml files, should the user not have set up metrics in dbt. Committed from the outset to try not to have lock-in, by supporting dbt metrics.
Works well for developer experience as transformation and modelling work can be done in the same place. They will most likely enable graphs/dashboards as code, too.
Has APIs for using the metrics layer chosen (theirs or dbt metrics) elsewhere.
The standalone semantic layers
Cube is an open-source standalone semantic layer, with cloud offering.
Funnily enough, Cube started off trying to build something like Delphi in the pre- LLM world and built a semantic layer to enable this… then realised they could deliver more value from the semantic layer on its own, that integrates with many other tools:
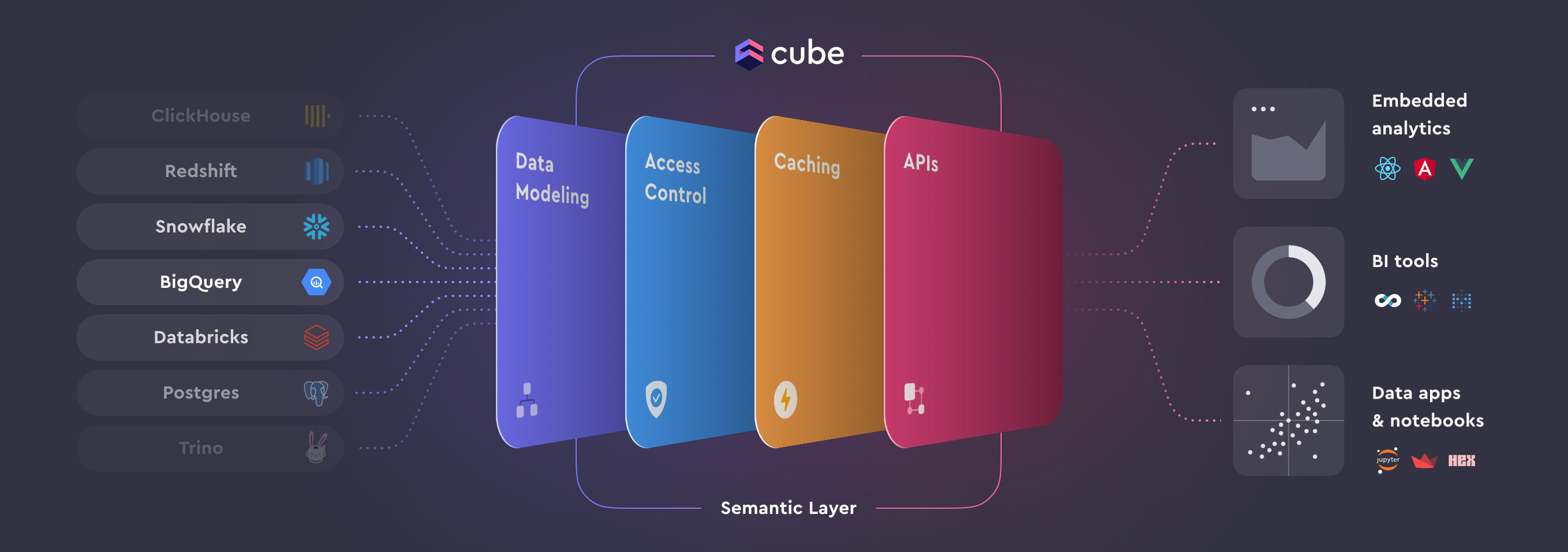
They have a huge number of Github stars (indicator of open-source usage) and within months of releasing Cube Cloud, have hundreds of customers using the platform. They have carved out a niche with embedded analytics, as you can see with their React/Angular/Vue support, and this is what they are best known for to date. However, their platform is obviously very well-suited to internal analytics/BI too.
Their semantic layer supports entities as I covered in my last post, and is therefore a true semantic layer. They have robust APIs (SQL, REST, GraphQL), state-of-the-art caching, plus access control designed for a semantic layer. dbt metrics can be exposed via Cube APIs now and I’m sure MetricFlow will follow in the future. While dbt Labs are choosing their path forward in this regard, this could be a great solution for those wishing to adopt dbt Metrics but who can’t use the existing implementation, or can’t wait until the new APIs are released.
I didn’t cover caching and access control with the semantic layers built in to BI tools, as, even if they have these features, they are designed to work within the context of the BI tool and not specifically for the semantic layer.
AtScale are a proprietary SaaS semantic layer; serving some very large enterprise organisations, with huge request volume. They integrate with Excel, Power BI and Tableau, amongst others, which are the analytics interfaces of the large enterprise segment.
In many ways, AtScale’s success at this level shows that semantic layers can be of tremendous value to enterprise customers. This could be because enterprise customers are better equipped to handle larger and more complex data stacks than SMBs and have such complexity in operations that semantic layers become a ‘must have’ piece in the data stack.
They talk about analytics governance, which cover the benefits around consistency I mentioned last week:
Analytics governance goes beyond security and access control. Consider how to create a level of centralized control and consistency that lets data leaders empower business groups to build their own data products while retaining a single source of truth for key enterprise metrics and safeguarding critical data assets.
Is this product-market fit for the standalone semantic layer, on internal analytical use cases (Cube already has this for embedded analytics)? Yes.
They don’t have technical documentation to explain how their platform works in detail, as they sell to larger enterprises and much of this communication happens in the sales process. At their scale, they will have performant caching, access control and APIs.
Their data modelling has been around a bit longer, as they were founded in 2013 - much earlier than Transform, Cube and dbt metrics. Whilst it allows you to do everything you need to do, it is more verbose than others, in order to provide the level of configurability required by large enterprise. For example, data asset to view mapping, relationships, dimensions and metrics are typically defined in separate places rather than with the data asset. For orgs with simpler requirements than large enterprise, MetricFlow and Cube will provide a nicer developer experience.
dbt/MetricFlow
I won’t cover the original implementation of the semantic layer by dbt following onto the Transform acquisition, as I have spoken about this plenty already. There has also been an AMA on this.
We’re still waiting to see what exactly the new APIs with caching/access control features will look like, and what form they will take. Transform’s MQL API currently uses GraphQL and uses Postgres as a cache.
I expect there will be some big announcements in San Diego, at this year’s Coalesce 😎.
As I mentioned in last week’s post, MetricFlow assumes entities exist in your data model and it doesn’t work well if they don’t, thereby enforcing entities, which is a good thing. However, it will require a good deal of maturity in your use of dbt to produce consumption tables that resemble an ERD.
dbt is unique in this list of standalone semantic layers, in that they are now the ubiquitous way to transform data, too. As I described above, it is better to define the semantic layer alongside transformation work, as the contexts hugely align. I think this is reflected in how Cube has supported dbt metrics definitions.
Looker Modeller
Newly announced, but very much anticipated ahead of the recent announcement. While this is indeed a standalone semantic layer with APIs for use elsewhere (of course it’s GCP), and support for multiple BI tools and not just Looker or Data Studio, I would be wary of favouritism towards BigQuery.
GCP’s main draw is BigQuery and spend on it results in 600% extra spend elsewhere in GCP, on average. While I would be fairly certain that GCP will be ambivalent about what is downstream of Looker Modeller - as it will still drive BigQuery spend regardless - they will try to drive upstream use towards BigQuery and away from Snowflake/Redshift/Databricks: money talks louder than words. Whether this is through carrot methods like incentivised migration with help to migrate and initial discounting, or stick methods like lack of feature parity or even outright lacking support. The carrot will come first, but if the cloud race takes setbacks, the stick will follow.
OLAP cubes (various implementations)
I hope we are in agreement that things like OLAP cubes in their original implementations (like Microsoft SSAS) aren’t a good idea going forwards, so I won’t cover them as an alternative metrics layer, although they are one.
Next week, looking at what else could be a semantic layer, thoughts on the future and interactions with LLMs.
Hey David, good stuff
You have a great series of articles about the semantic layer; I'm learning a lot from you.
i have one question, tho.
what you meant with
> I hope we are in agreement that things like OLAP cubes in their original implementations (like Microsoft SSAS) aren’t a good idea going forwards
I really like to play around with the different implementations so far. But it is still a lot of playing around. I have a bit of a LookML past with all the pros/cons (you covered them well).
From the integrated ones I enjoy the Lightdash one most - it's already where I usualy prepare the data (dbt), their approach makes more sense than the dbt one (at least for me). And like you, I am hoping there will be more people asking for charts and dashboards as code.
In two new projects I am starting to work with Cube in small scale scenario and so far I really like to work with it. But I am still scratching the surface.