
The Human Interfaces of Data - Abhi
Abhi Sivasailam of Levers



This week’s guest is Abhi Sivasailam, who is CEO and Founder at Levers Labs. Abhi has given great talks on “Designing and Building Metric Trees”, “The Modern Data Team” and most recently spoke at MDS Fest on the topic: “GAAP for data and the SOMA standard”.
Abhi and I first started talking after we were both on a dbt Labs panel (the topic eludes me), and I’ve been fortunate enough to catch up with him the last couple of times I was in the US. We share a background of leading data teams at the height of MDS, and subsequently moving to become founders in the space.
Abhi’s thoughts on how data and growth teams should work, metric trees and their organisational impact, getting buy-in for data in an org… are at the cutting edge of data thought leadership.
The Questions
Give us a bit of an introduction about yourself:
Education
Undergrad: Economics, Mathematics, Statistics
Graduate: Statistics
[David Jayatillake - Why did you study the things you did? What were you like growing up that led to this?
Abhi Sivasailam - I was always into social sciences (psychology, sociology, history, political science) and came to see economics as the most robust of all of these. Then, added the math and stats to be a better economist. No coincidence that I ended up in growth+data - it's empirical, applied social science!]
How you came to data in your career
Like lots of data people, I'm a failed would-be academic. I was planning on getting a PhD in economics and got distracted along the way and landed in the private sector. There, I realized that it was never really the economics that was most appealing to me, but the applied empirical work and the opportunities for robust, diverse, interesting, and impactful empirical work were far richer in the private sector.
An overview of the places you have worked in data and what roles you have held
I started out in politics, in the belly of the beast in Washington D.C. There, I spent a few years applying my empirical and economics training towards education and tax policy research. I also ran some polling for national and state campaigns you may have heard about. Alas, like many who spend time in D.C., I came to politics hoping to live out a “West Wing” fantasy and left when I realized I was living a C-plot of “Veep”.
From there, I went on to management consulting at Accenture, to work on large-scale statistical models to help Fortune 50 companies better engage their customers. Think lots of propensity models, survival analysis, media mix modeling and the like. This was work at enterprise scale, with truly “big data”, complex challenges, and lots of operating leverage. It was helpful to see relatively early in my data career what it looked like for “data” to drive real and significant enterprise value, and sometimes even make a difference in customer lives.
Hungry for even greater impact, I wanted to go to where the action was – in techland. So, in 2013, I joined an early stage startup as the first data hire. I was hired as a data scientist and that’s what I expected to do. But, in my first week, I learned data work looks very different at startups. Statistical rigor would have to take a back seat to “good enough” analytics; R and SAS would have to be put away in favor of spreadsheets and BI tools; and data was no longer organized in neat enterprise data marts – if I wanted data I would have to get and organize it myself. This was highly unfamiliar territory.
[David Jayatillake - Did you have any moments where you were asked to do things you felt weren't on the job description, and were unhappy about it? What did you do?
Abhi Sivasailam - At this point in my career - I was just enjoying all the novelty! That said, after my experiences here, and with some of the companies I ended up consulting for/advising while in this role, I did end up formalizing a list of questions that I gave my subsequent employers before accepting an offer. I still do this (and recommend others do this) - and it’s a great way of making sure you're set up to be happy. An earlier version of these questions, from several years (and jobs) ago, is now at the very bottom of this post.]
Fortunately, I wasn’t alone. Lots of people were in similar positions and forming communities and starting products to help their peers. Just a couple of years earlier, Amazon had launched redshift and it was starting to pick up steam. And just the prior year, two little-known companies called Fivetran and Looker were launched, to help folks like me manage their new, generalist data responsibilities.
And thus, I became an early beneficiary of the wave of the so-called “modern data stack”. That enabled me to build out a team of analysts, scientists, and data engineers around me and start scaling to meet the needs of the company. Eventually, those needs took me to another newly-emerging job title whose sexiness was giving “data science” a run for its money: growth hacker.
[David Jayatillake - the MDS is getting some flack today - how do you feel about it now and in light of how it helped you in the past?
Abhi Sivasailam - No question - the "MDS" helped a generation of startups get value from data far faster and cheaper than they could have otherwise. If I'd had to roll a Hadoop stack to process data when I joined techland, we'd have never gotten off reporting in Excel, running off VB macros...]
I liked the data work I did, but it always felt incomplete, and the impact often felt hypothetical – more academic than practical – and if I wanted that, I would have stayed in policy research. But here was “growth”! Here was a natural symbiosis: growth gave data purpose; data gave growth context and rigor. I started running growth experiments and slowly merged the functions, which would then lead to becoming a recurring theme for me in future roles. In every role since, I’ve ended up owning both growth teams and data teams, and keeping them closely aligned. Most recently, I did that at Flexport, where I helped scale the data org (and company) through hypergrowth.
[David Jayatillake - You've spoken about how you think Growth+Data should be managed together. How does this work with the other consumers of data in the org, like Finance and Product? Do they feel more isolated from data as a result? If so, how do you address this?
Abhi Sivasailam - Colocating Growth+Data doesn't mean that data can't still support other functions. Every function gets dedicated resourcing (though we typically make them pay for the headcount they want!)]
Hypergrowth is great fun, but is also exhausting – I left last year to go on a sabbatical and, among other things, go motorcycle through India to finally finish a cookbook I was working on (DM me for details). When I came back, I decided to dip my toes back into employment by consulting/advising, and, finding those waters too calm, then decided to start a company, which I founded earlier this year. I now head up Levers Labs, where we build tools to help companies build quantitative models of how their business works and then to use those models to drive how they plan, prioritize, execute, and innovate. If we succeed, the hope is that data practitioners can focus on analyses and data products that are higher leverage (and more fun) than they are today.
Can you describe the human interfaces you have had as a data person:
I love this question because it's fundamentally about systems not tools; the socio, not the technical. After all:

Most of my time as a data leader has been spent defining process architecture – not technical architecture. There are dozens of processes, small and large, I’ve implemented over the years, but three loom largest:
“Data in the Product Lifecycle”
Business Reviews
Planning Cycles
“Data in the Product Life-cycle”
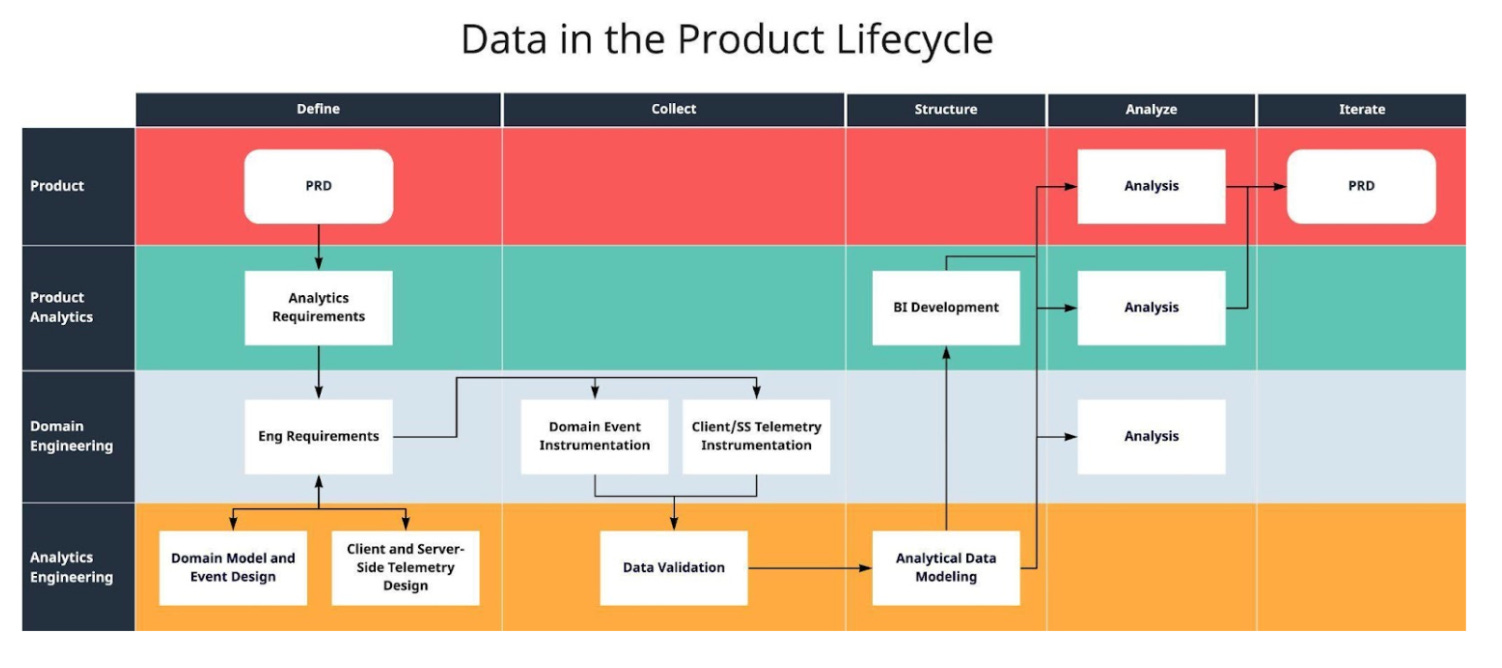
For me, the data life-cycle begins with the Product Requirements Document owned by the relevant Product Manager, and which details feature development needs. Each PRD must include an Analytics Requirements Document that is co-created with the relevant Product Analyst(s) and which details:
Key operating metrics and KPIs that must be trackable as part of a functional release; and
Exploratory questions that the PM/Analyst anticipate themselves, or their partners are asking
Product Requirements give rise to Engineering Requirements, but, importantly, Engineering Requirements contain data requirements expressed in a Data Design Document. Features can’t be considered complete without a DDD!
[David Jayatillake - How would you guide a data person to get this to become compulsory? In many orgs, if someone in data said this was necessary they would just get shouted down or ignored. Does looking after Growth give you extra clout to say certain things must be so?
Abhi Sivasailam - This is the question I get most often. And my answer is always: incentive compatibility makes the world go round. The "Data in the Product Lifecycle" flow requires a ton of buy-in. To get that buy-in, I just try to position these asks as being in the best interest of the partner orgs. At Flexport, we knew that Product really wanted great self-serve analytics out of Amplitude, and we worked hard to position this as the best way to make that happen; for Engineering, we positioned this as an opportunity to help accelerate their shift over to microservices. Much is possible for data teams, if they take the time to think carefully and sometimes creatively about incentives!]
With respect to data, every new feature a product team creates introduces some combination of the following side-effects:
Creates or necessitates the collection of new data
Mutates or alters old data or prior representations of data
Raises new questions of existing data
The Data Design Document is intended to thoughtfully manage these effects, up front, by defining the necessary data collection and modeling requirements.
There’s more to it, but, for brevity’s sake, I’ll point you to my Coalesce talk where I talk a little more about the process in the latter half.
At any rate, the “Data in the Product Life Cycle” process has been invaluable in making sure data is treated as a product – and not a byproduct.
Business Reviews and Planning Cycles
Much has been written about running great Business Reviews. As well, about planning cycles. Alas, these topics are too rich for me to cover fully in the space provided, and so I’d recommend that interested readers should start by perusing the body of work available on the topics (DM me for more recs). That said, I’ll share a few of the most important points of emphasis for what I’ve seen work well and what I think data teams must get right, vis-a-vis The Big Two.
Business Reviews
A common recommendation for Business Reviews is to have a pre-read, with sections owned by the relevant teams participating in the Review. I agree, and the structure I recommend for these sections is as follows:

Importantly, for data teams I lead, I insist that the contents of the metrics section be wholly owned by the data team. Trivially, that means a data person is pulling the numbers for that section. Less trivially, it means the data person decides what the metrics are for that section and how they are defined.
In practice, that means that the leader of a business function must ask for the data team’s approval to include a metric in their business review. This is a radical proposition for most companies, but an important one for me, and I’ve found this to be transformational in making sure teams are pointed towards the right outcomes.
[David Jayatillake - Again, how do you negotiate/persuade this? Do you have stories of where there was resistance to this concept? What did you do about it?
Abhi Sivasailam - Take it to the top! The only way to make data-driven rituals take hold in an organization is to get the deep buy-in of the top of the leadership chain. And the top of the leadership chain is usually very incentivized to implement rituals like this - especially if it doesn't require much work from them! To get this to happen in the tech org at Flexport, for e.g., I went straight to the CTO.]
Planning
The classic planning cycle looks something like this:
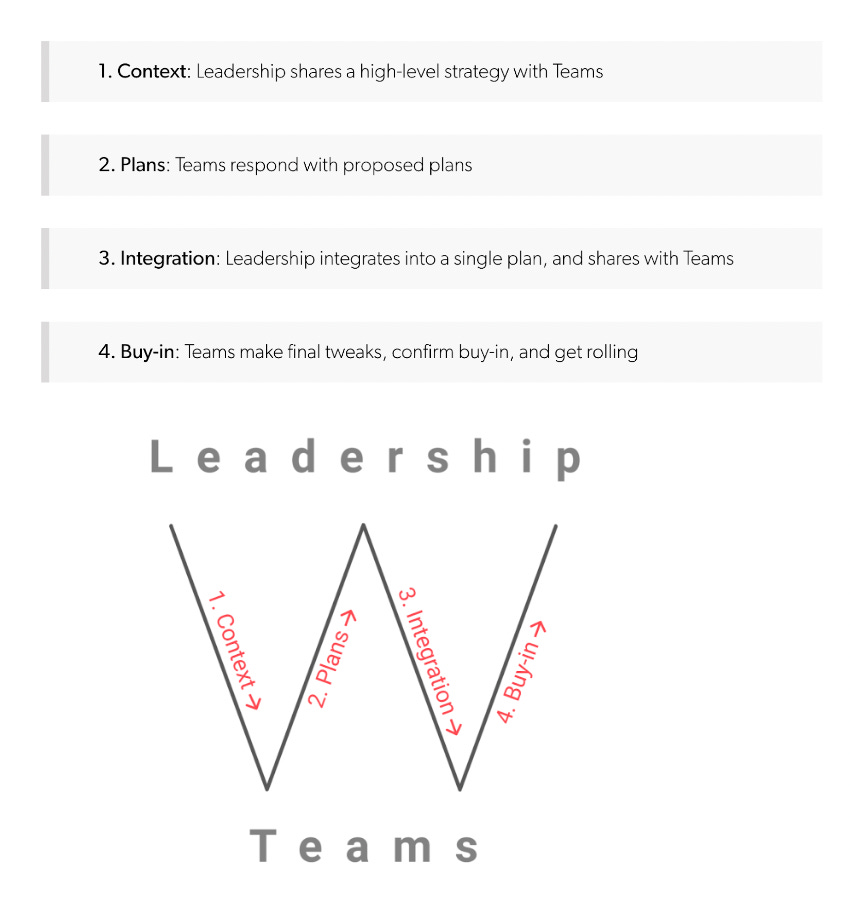
In most companies, the data team’s involvement in this process is at the “Planning” stage and consists of helping teams perform analysis to inform initiatives and setting up instrumentation and reporting for metrics to track those initiatives.
[David Jayatillake - In my experience, many companies outside of tech, who don't value data so highly and even some who do (Lyst, for example, didn't see the need to have a VP of Data - only VP and above were included in Senior Leadership discussion, including planning), don't bring the data team into the planning stage. Lots of planning at companies isn't metrics focused, there is a lot of hand-wavy: “doing X will improve Y”. How do we get past this, as data folks?
Abhi Sivasailam - Here, too, I'd make a bold pitch to the top of the leadership chain. And if you want help doing so, my DMs are open :)]
Contrast that with how we ran planning cycles for the Technology organization at Flexport:
Context: Data is in the room with Leadership when strategy is being set and strategy cannot be set without the input of the data team. The data team does critical analysis, up front, to validate whether possible strategies are viable in light of market and internal data. When a viable strategy is finalized, the data team defines a set of north stars that serve as signposts for the strategy and relate those north stars to a common measuring scale (in our case, Net Revenue).
Plans: The data team shares ownership of defining metrics for product teams. The PM and the Analyst on a team have mutual vetoes for any proposed metrics. Analysts derive and are explicit about the mathematical relationship between team metrics and the north stars. Team metrics are set before any initiatives are planned and each initiative must map to a team metric. Analysts forecast the impact of each initiative on each team metric.
Integration: The Data Team takes the proposed initiatives and their forecasted impacts and finalizes a stack-ranked list per our common measuring scale, for leadership to review. Data is in the room with leadership, weighing in, while the final cut-line and budget allocation decisions are being finalized to send down to individual teams.
Buy-In: Analysts partner with PMs to adjust metrics and team forecasts in line with the final approved budgets.
Here, too, this level of autonomy and latitude is a radical proposition (and admittedly a little heavy-weight) for most companies – and it wasn’t easy to land. But, here, too, this kind of process was absolutely transformational.
What are you doing now in your current role as X, that helps make human interfaces in data better?
Levers Labs is building tools to help companies build models of their business (starting with businesses that can be highly standardized, like B2B SaaS) and then to use those models to support operational use cases like the business reviews and planning cycles we talk about above. It’s not as easy as it sounds to get those rituals right and to make them valuable and sustainable. In particular, we’ve found that it takes having enough of the right metrics and easy and in-context access for operators to ask questions like: “why are these metrics changing”, “where are these metrics going to land next period?”, and “what can we do operationally, to meet our goals?”. We make it easy to answer those questions and to bind them into key data-driven rituals. If that’s of interest, please reach out!

 | A guest post by
|
Access to the Data Design Document is restricted, is that expected?
https://docs.google.com/document/d/1Xg4a-93PDieAB2wA2ibypnBFJ3rCuSZzAMgR-KGGfFo/