
Unit Tests
Looking at dbt's new unit tests feature


In computer programming, unit testing is a software testing method by which individual units of source code—sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures—are tested to determine whether they are fit for use.[1] It is a standard step in development and implementation approaches such as Agile.
I’ve been someone who has advocated for the use of dbt tests for a long time, as well as data observability tools, to help guarantee data quality. Using both types of tools can get you a long way.
As I’ve mentioned before, I’ve helped Pete Fein with his popular Carnegie Mellon University - Heinz College course on Data Warehousing. Most of my contribution was the dbt project part of the course and associated materials and questions related to it.
Pete has a SWE background, whilst I have a general data background and we meet in the middle at DE - while my knowledge of SWE has improved over time, it’s still really at novice level. When we’ve spoken about dbt tests in the past, Pete has highlighted that dbt tests are not true unit tests. At first I didn’t know what he meant, but upon clarification, I could see that dbt tests are more like integration tests, which test that a component of a project is working both from a function and a data input point of view.
When a dbt test fails, you aren’t sure if it’s because of a function (model/macro) change or because the data has changed in nature. Even if there has been a recent function change, you can’t be sure if this is what caused the test failure. Unit tests, on the other hand, only test the function - they don’t test the data at the same time. They are designed such that you can change a function, expect the same results in a specific scenario, and test whether the function still behaves the same in this scenario. The data input remains fixed. If you want a new behaviour, you have to write a new unit test.
I’ve even written some unit tests in the few contributions I’ve made, but it’s easy to forget that you are providing a fixed dataset to them when you explicitly put the values for the data in code - as a data person, I’m so used to data being somewhere else other than my code.
My natural inclination towards how a unit test should work in dbt is:
A fixed dataset would be provided, probably as a dbt seed or something similar, for the specific purpose of unit testing input data. Unlike in SWE, it’s less likely for this to be in code, as it could end up being quite verbose for a wide table etc. In SWE, it can be quite helpful to see a small snippet of data, like a filled in class, as you can understand the test data at a glance - this is rarely possible in analytics engineering. I would expect that even small datasets for unit testing in AE would be many columns wide and have enough rows to test the different outcomes in the test - too cumbersome to store in code and doesn’t provide the “at-a-glance” benefit I described above.
The exception is for macros, which can have very simple input data - the input parameters. Macros take input parameters and generate a string output. It’s possible for the input parameters and output, for a test, to be in code. As I haven’t looked at the new unit testing feature yet, I’m not exactly sure if it’s geared towards unit testing of models, macros, both or something else.
You could also imagine a capability to sample an existing data source to create your test dataset during development, which then remains fixed as a seed or equivalent in the repository.
Then the definition of the unit test would include the input data as a ref, seed, source or something new, as well as the macro or model to be tested.
If it was a model being tested, then it is as simple as running the input dataset/s through the model as if it was the table/s it was referring to. There would then need to be an output dataset to compare it to, as well. So, the definition of the unit test would need to also include this.
The idea is that it makes debugging much easier - code changes which break the unit tests don’t get past development. Therefore, in theory, it means that OG dbt test failures are driven by data issues rather than code issues.
I haven’t looked at all at the new dbt unit test feature, it kind of snuck up on me… I didn’t expect anything like it to be released in the near future. So, I’ve written everything up to this point without looking at it.
![새랑태🌻 | [semi-hiatus] ♡ on X: "@bts_bighit IS #2018BTSFESTA MATRIX THEMED?! I ALWAYS THOUGHT @BTS_twt WAS INSPIRED BY 'THE MATRIX' & 'ALICE IN WONDERLAND'. THE LIQUID MIRROR REFERENCE WITH JIN, SYMBOLIZING THE](https://substackcdn.com/image/fetch/$s_!wUzD!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F213ce245-ab2e-4371-8ae3-aa8ec773e5a7_1200x500.jpeg "새랑태🌻 | [semi-hiatus] ♡ on X: \"@bts_bighit IS #2018BTSFESTA MATRIX THEMED?! I ALWAYS THOUGHT @BTS_twt WAS INSPIRED BY 'THE MATRIX' & 'ALICE IN WONDERLAND'. THE LIQUID MIRROR REFERENCE WITH JIN, SYMBOLIZING THE")
Through the Zooming glass
There is a Github issue which encapsulates most of the information shared by dbt Labs and it also has a recording of a webinar I watched in order to understand the new feature. If you want to learn more about the feature, I recommend watching the recording, perhaps on 2x to keep it under half an hour - it’s a more digestible story than reading the Github issue. Grace Goheen’s demo is the key part to watch.
The way the implementation works is similar to how I imagined it would, but with a few key differences and benefits.
For reference, this is the model example for unit testing that dbt Labs have used:

Unit tests are defined in yet another yml file in your dbt project:

This is pretty similar to how I expected it might be implemented, but there are some key things to point out. As you can see, the default way to store your test input data is in the yaml file directly, in the dictionary format shown above. It is also possible to use in-line CSV or separate CSV files for this. Where the separate CSV files are used, they are a new object in a dbt project called ‘fixtures’. Fixtures are distinct from seeds, and likely won’t be materialised in your DWH, as they are small and only needed for unit tests. Significantly, unit tests won’t run on expensive DWH compute, they will run locally or in a Cloud IDE environment… ie no extra cost.
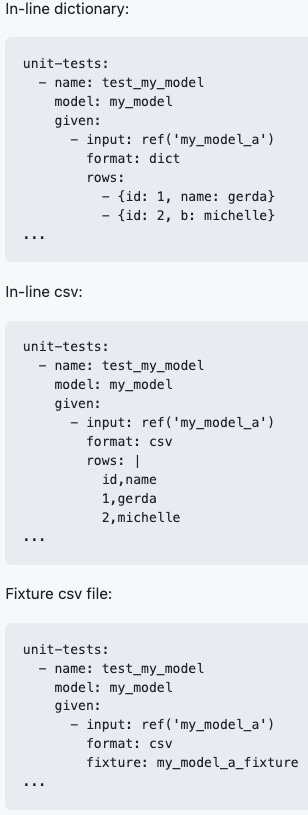
As I mentioned above, I thought using an in-line method would be verbose in a repository file and wouldn’t achieve the at-a-glance nature that’s desired. However, one thing I wasn’t expecting is that you can test individual components of your model (columns, in this case) separately.
The example above only really tests the is_valid_email_address column, which has some complex logic. The test input data and expected output data need only contain the data necessary to test this column - you don’t need to include all the columns from the model for either input or output data . What this means is that it is possible to include much smaller quantities of data for your unit test - fewer columns with fewer outcome permutations as rows. Therefore, it does make sense to store the data with the test definition and have it easily visible without referring elsewhere.
When I had envisioned unit tests beforehand, I had thought of the whole model as a function - which you can still do if you want - but you can actually treat individual parts of model, such as how a specific column is defined, as the function to test.
I’m not sure how the internals of unit test work, and if it works with aggregates (the example model doesn’t have aggregates). With aggregates, the grain of data matters for unit testing and you can’t remove fields which would have been in the group by clause, without knock-on effects for the test. I have asked, but I suspect it would be up to the engineer to design the test well.
You can run unit tests separately from OG dbt tests - which are now being referred to as data tests - with a command like this:
dbt test —select test_type: unit
With dbt build, unit tests will now run before materialisation, to prevent bad logic while generating data and also saving cloud DWH costs.
This is an open-source feature that is going to be released as part of dbt 1.8, but I’m sure that dbt cloud will offer enhanced support for the feature as part of their CI/CD Github app and IDE.
Overall, this looks like a good addition to dbt core and I think analytics engineers should use it. It looks like a great feature to add to the CMU course project I mentioned at the start - it’s good development practice to teach to aspiring analytics engineers.
Here are some features not prioritised for initial release (includes unit tests for macros, not a biggie), taken from the Github issue:
Unit testing seeds, snapshots, analyses, or macros directly (they can be tested by making a passthrough model, though!)
Unit testing the outputs of CTEs.
This is arguably akin to testing private methods - which is a debatable practice in software engineering. Sometimes it helps us sleep at night, but it’s structurally sensitive and is brittle to implementation changes.
If it’s really complicated and critical enough to warrant a test - it should probably be refactored into a separate (private, ephemeral) model so that it can be documented, reviewed, and tested independently.
Unit testing the inputs/outputs of MetricFlow queries.
Assertion that a particular jinja execution error is raised, given specific inputs (similar to what pytest.raises provides).
Excited for Spring 2024! Unit testing as a native functionality is going to be huge
So cool to see dbt help nudge data teams to operate more and more like software teams