
Breaking and Non-Breaking Changes
Exploring how sqlmesh handles change in development

Yesterday, I covered how sqlmesh virtual environments work and how they are a foundation for many of the benefits of using sqlmesh:
sqlmesh plan

I finished looking at model kinds in sqlmesh yesterday and will begin today by finally running the sqlmesh plan command!
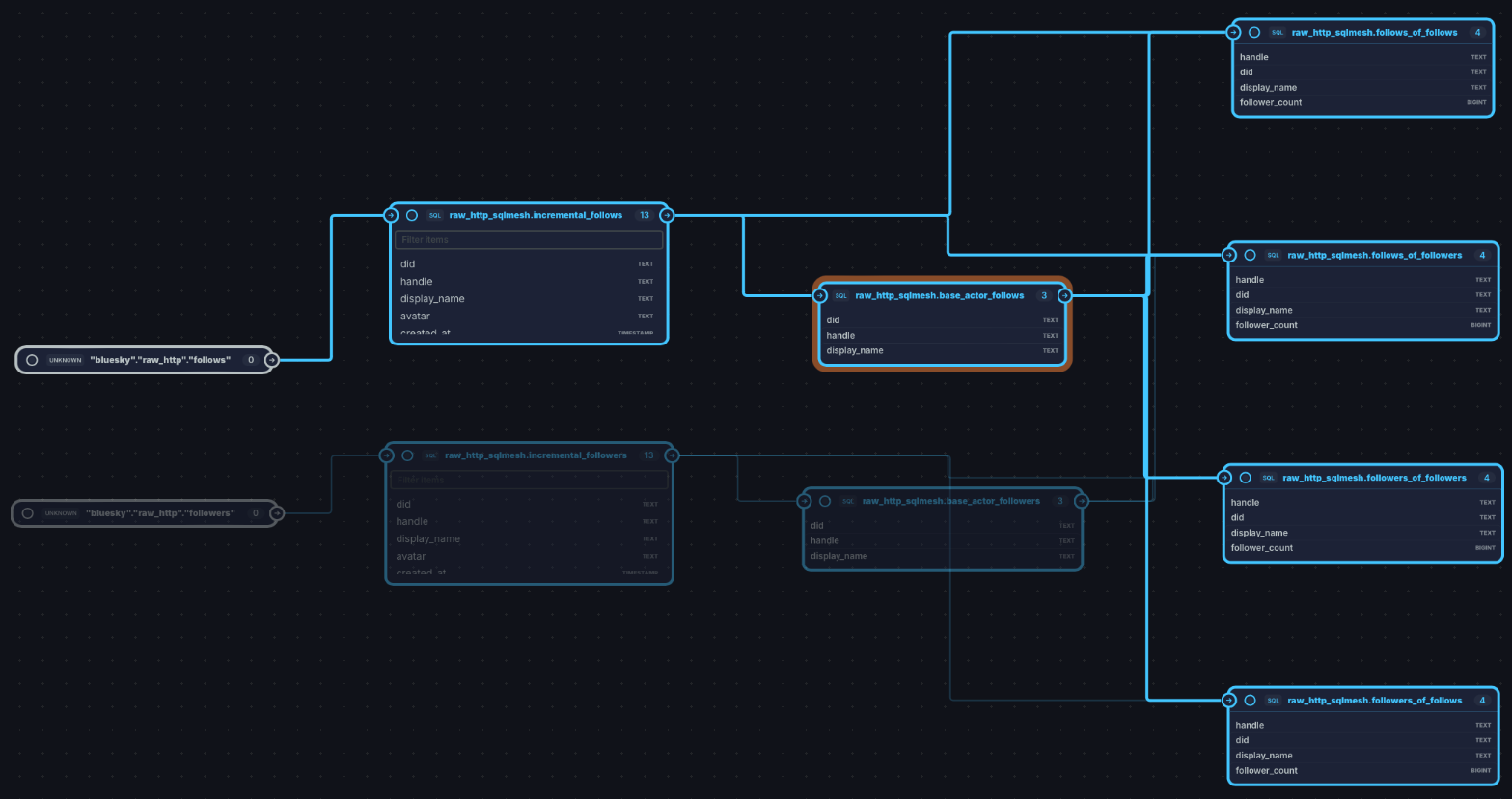
As you can see from my DAG above, I’ve added1 some new models that use the raw data I ingested to learn some useful things. I’ve made embedded models which find the follows and followers of the base actor. Then, with these embedded models, I have made some view kind models which find:
Who the base actor’s follows follow themselves
Who follows the base actor’s follows
Who the base actor’s followers also follow
Who the base actor’s followers are followed by
All four are grouped by frequency and filtered to accounts not already followed by the base actor.
Audits
Audits in sqlmesh are like tests in dbt. They are data tests based on an assertion, like uniqueness, and completeness… sqlmesh also has tests which are more like software engineering unit tests, which I’ll cover later.
Audits are set in the model file they apply to and don’t need a separate file like in dbt.

So, let’s add some audits to a couple of my models to the left of the DAG.
audits (
unique_combination_of_columns(columns := (handle, actor)),
),
I’ve added this audit to incremental followers and follows as this is their unique_key, so it should be true. Now let’s run sqlmesh plan:
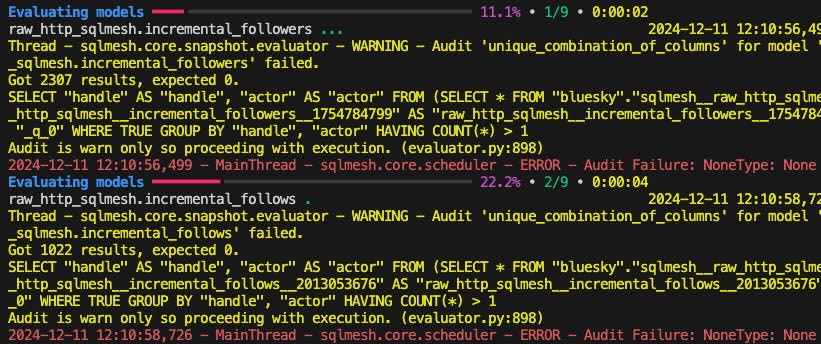
As I suspected, when I was developing the pipelines using dlt, I ran them a few times and duplicated the data. So, I need to slap a qualify at the end of the models to deduplicate the input.

Now, these are tricky changes to manage. They are breaking because the nature of the data has changed, and downstream models will be affected, but the columns are all present and named the same.
Every time a model is modified directly, SQLMesh automatically categorizes the change as “breaking” (downstream models are affected) or “non-breaking” (only the modified model is affected) based on the change’s impact on downstream models. This is possible due to the platform’s ability to understand SQL semantically, at the AST level. By comparing the current model version with the previous one we’re able to compute a semantic diff, which SQLMesh further analyzes to understand the impacts it would have on downstream models.
For example, adding a new column is not considered to be a breaking change, but removing or modifying the existing one is.

So, let’s test sqlmesh’s ability to find breaking changes, like the tricky one I just introduced:

It has accurately identified the downstream models for which this constitutes a breaking change, automatically leveraging its semantic understanding of SQL. Aside from refreshing all children of the altered models, there is no way to achieve this automatically in dbt, which is both costly and time-consuming. sqlmesh simply prompts you to confirm if you wish to backfill the affected tables as well, and proceeds to do so if you agree. Parsing the SQL of the models to ascertain precisely what they impact and what they do not is a complex task that has been simplified for the engineer.

Let’s try a simpler one. Here, I commented out the description column in the incremental followers model. This column is only directly referenced in the dim_profiles model.

sqlmesh plan immediately highlights that dim_profiles has been directly modified because a column depends on the incremental_followers description field, highlighting the line in the model. This is a very valuable automated application of column-level lineage - far more valuable than a pretty DAG (although we like these, too!).
The indirectly modified models downstream aren’t actually broken by this change; however, sqlmesh has addressed this by implementing partial breaking changes that acknowledge where downstream models aren’t affected by a potentially breaking change upstream, which is available for Tobiko Cloud customers.
Currently, this approach doesn’t extend beyond looking at each model as a whole. Soon, however, SQLMesh will categorize changes per individual column instead, thanks to its ability to determine column-level lineage.
This will allow an even finer balance between correctness and efficiency, since changes like removing a column that is not referenced downstream will no longer be categorized as “breaking.”

I also tried adding a fixed string source column, which should be a non-breaking change. As expected, the downstream models are labelled as having a non-breaking change. The only model that is then selected to run is the one with the non-breaking change, and all downstream models are left alone.

Windsurf did a very good job at building sqlmesh models I described. It hallucinated the odd bit of syntax but saved a lot of time and keystrokes. I used it to scaffold all of them and didn’t have to make any edits for a few.