
Model Generation
A big feature release by SQLMesh


One of the things I’ve written about before is how I’ve used dbt macros to generically create models. The problem with this approach is that there is no innate way to feed an array of parameters into a dbt macro and have this generate that many models in your DAG. It always involves creating that many .sql files in your dbt project… which, to be honest, is annoying and tedious. I’m not the only one either; others have asked for this feature in dbt Core, but it’s been years, and no good solution has been offered or released so far.
Here is an example of the macro I built, which I then created around 50 dbt models with - simply config plus a macro call:

Here is an example of one of the models that were effectively generated by the macro:

That’s it. The whole model is the macro, along with some configuration that would be easily generated if that were possible, too. As I said above, I needed to create 50ish of these little models. You might say it’s not that much effort, but isn’t the whole point of using a framework like dbt or SQLMesh to write DRY code? I feel like I did my part in this by making the macro. Still, the framework has let me down by forcing me to make many files that simply refer to the macro with parameters input, which could easily have been iterated from an array of such parameters or tuples of parameters.
Another issue with manually creating all the models is that if you make a breaking change to your macro, you then have to go back and manually update all the models, which I ended up having to do. This process is brittle and could easily lead to run failures from overlooked manual fixes.
Two years ago, bashyroger1, who posted a GitHub issue on dbt Core about this very topic, replied to Jerco’s explanation as to why the dbt Core team were reluctant ideologically to release such a feature:
Thanks for your extensive comment @jtcohen6 , I have been giving your writings a bit more thoughs
Regarding your comment in act 3:“After all, maybe dbt cannot be—ought not be—a data warehouse automater itself, but merely the best-possible substrate for "true" DWH automation?”
I still think it can / should be partially. Partially by indeed introducing 'template models': models with a recursive (Jinja) loop that can spawn the creation of multiple models files.
For us it now feels disjoined that we, just to get this done, have to write our own custom python code that enables us to do this when ALL that is missing is this 1 meta model to n child models step. As in: we have now implemented a solution that is akin to what @erika-e mentions, but it feels over-engineered to us...From what I can infer about your writing, this initial request would largely be fulfilled if #3428 were implemented.
Regarding your comment on parse time / vs execution time problem: those template models would not have to run at execution time initially. As a developer, I would purely see them as a way to automate the creation of multiple model files from a template, something that the current codegen package indeed cannot do.
Practically, I would expect a command to exists like:
dbt generate -s my_meta_model.sql --args {args}
It would create / update 1-n children, REAL dbt models that after creation obviously would have to be compiled.Then later, further along the road, I would see them be added to the execution context:
-The
dbt generatecommand would be allowed to be used in an execution context, requiring a 2nd compile pass when invoked.-The child models, if all valid would be 'lazily' auto-committed to the same branch the code is running on.
I still didn’t think generating individual model files from the model generator would be a good idea. They would then require maintenance, and you would likely need to edit them in bulk or delete and recreate them. Additionally, having a model file for them is misleading, as an engineer never created that file, and it doesn’t govern the model's logic without detachment between the generator and the model, which presents the issues I’ve already described.
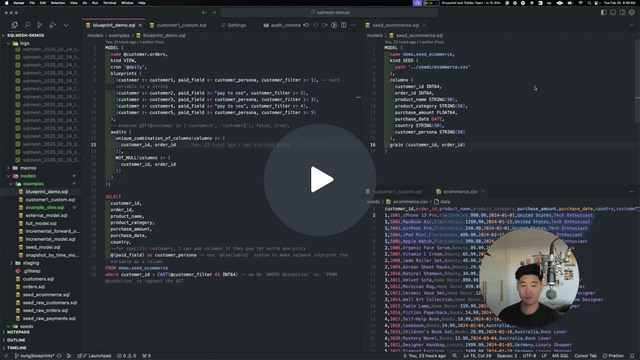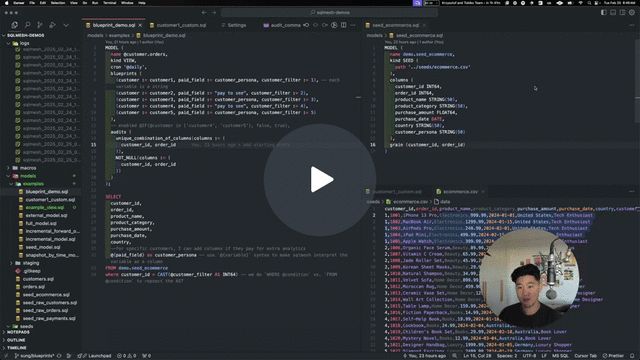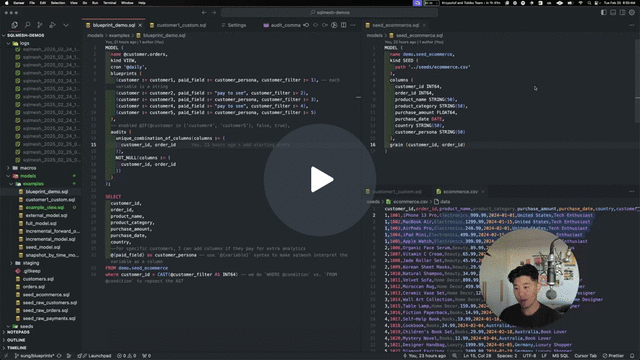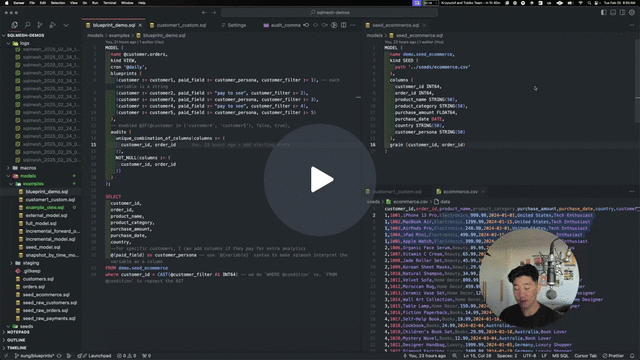
At the end of the SDF post, I mentioned my belief that SQLMesh now possesses a significant speed advantage, allowing it to implement new product features quickly and widen the gap over SDF/dbt. It appears that this is indeed the case: SQLMesh just released SQL model blueprinting:

This feature is exactly what everyone wanted, and it feels so clean and simple. You can see exactly how I could have used it to generate the Streamkap CDC models I shared above. You could have the macro as the body of the blueprint model, the incremental config in the config of the blueprint model and then the tuples of parameters in the blueprints config of the blueprint model.
This is clearly the right way for me. It doesn’t generate loads of model files—it generates logical models that will exist only in the DAG. This means that changing the generated models only requires changing the original blueprint model - which is correct, as this is what generates them anyway.
I don’t understand why releasing this into dbt Core was so hard when it has been requested many times. I know that there is a great deal of careful consideration, as you can see from Jerco’s comments in the GitHub discussion/issue, but there comes a point where this level of thought is just a blocker to action.
SQLMesh Blueprint Models Demo - Watch Video
bashyroger is the github username of Rogier Werschkull who is Head of Data at Coolgradient
I needed this feature a couple of years ago for definiting product event types dynamically but unfortunately there was no tool that supported it back then, glad to see sqlmesh implementing it!
I see the dbt's concern and IMO Terraform has solved this problem for infra without comprimising the flexibility long time ago by requiring the user confirmation before applying the plan and allowing users to put runtime contrainst in place.
I came seeking this solution after trying out SQLMesh and am pretty disappointed that it does not exist somehow for DBT. We really should not have to maintain hundreds to thousands of the same file. DRY it up DBT.
Unfortunatly, SQLMesh is still pretty rough around the edges with my datastore (Risingwave) and gets really painful to manage schema references to tables. Since my use case is model generation and apply for a streaming system and not the typical warehouse usecase, most of the environment and state management of SQLMesh is too intrusive. The UI doesn't really handle all of the generated blueprint models very well either. Maybe I'll wrap back around in the future and see if any of this has been addressed.