
Modellion
A DAG, not a Data Model

Let’s start with a TLDR; Medallion Architecture is not a form of data modeling.
It is associated with data modeling, and data modeling happens within it - as I will explain - but it is not a form of data modeling, as Joe Reis shared on BlueSky, here:

I am sure that Chris Riccomini does know what it is here, but was in the mood to provoke 😁. So, here I am taking the bait…
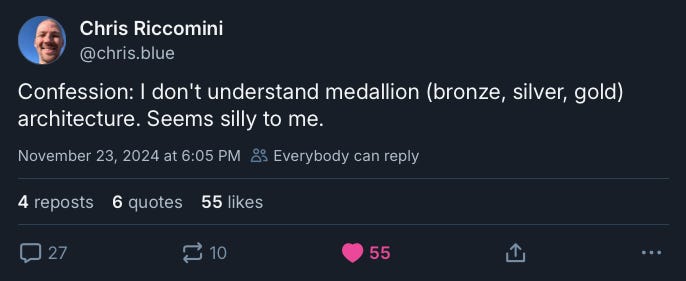
I think the concept of Medallion architecture has been around for a while as a product marketing term, but it has probably come to the fore because Databricks have been heavily using it:

As you can see, Medallion architecture is more of a high level DAG. You can think of it as a grouping of activities that you might see in a dbt/SQLMesh project. Many people organise their projects in this way already with raw (sources), bronze (staging) and subsequent folders in their project. Often, the folder structure dictates materialisation of tables in progressive schemas according to where they are in this architecture.
So what is bronze, silver and gold?
Bronze
Bronze layer is very similar to what most people call staging. This is where you deal with the nature and flaws of your data. Flattening nested JSON structures, casting, parsing needed parameters out of URL fields, using regex to fix some poorly-formed strings from a source system, filtering out test data, deduplication within dataset, deduplication across datasets… We’re trying to protect ourselves from future gotchas later in the DAG. Not all of the raw data should be made available in bronze, just what is needed by silver - bronze is not for use by consumers.
Bronze is also where we test our assertions about our data, such as uniqueness, completeness, allowed values etc. If we do it here, we don’t need to do it on subsequent tables which can rely on these assertions being true. We also should rename fields etc to be sensible and easy to understand for silver. Usually, a good amount of EDA goes into understanding how to do bronze layer work - the outputs of this can be documented or made assertions in tests. All of which become inherited benefits for those developing the silver layer.
Silver
I believe this is where your chosen data model emerges. Where we materialise a Kimball, Data Vault (or other) model - the point is that a relational model of some kind is built from bronze/staging tables here. Entity and event tables are materialised with clear primary keys and foreign key relationships, where sources are only bronze or other silver tables.
I think this is where slowly changing dimensions (SCDs) are handled, too - you might have a staging/bronze table which stores records of changes to an entity. However, it’s difficult to use for understanding SCDs. A silver table could be built which allows for inequality joins1 on from and to timestamps, to understand the state of an entity at a given time, from this bronze table.
Silver is where the relational model as you want it to exist, is formed.
It is possible to stop here and rely on analysts and other consumers to be able to use the relational model well, especially where it is relatively simple. However, as complexity increases, it doesn’t work and leads to big inconsistencies in the querying and interpretation of data.
At Cube, we have staging and mart folders/schemas. Funnily enough, our mart folder is incorrectly named - it isn’t like the gold layer business level aggregates, it’s much more like the silver layer data. We then use Cube’s semantic layer on top of the mart layer, which is really a relational model - a silver layer. Cube then negates the need for a gold layer, as we can define how the tables in the silver layer should be joined and aggregated. Pre-aggregations and caching in the semantic layer also negate the need for true mart tables/OLAP cubes, as performance and cost are well-managed this way.
Simon Späti wrote a good piece explaining some of these principles on Cube’s blog here.
You can tell the Databricks diagram above was made by product marketing and not data folks, as there is a subtle error here. Data quality doesn’t improve the whole way from bronze to gold. It improves through bronze and then stops at silver. There is nothing wrong with the quality of data in silver, and it is not lesser than gold in quality. It is less accessible than gold: you have to know how to join it and use it, you have to know how the data model works. Gold abstracts this from the consumer.
Gold
This has typically been where pre-aggregated wide mart tables and small star schemas of fact and dimension tables have been made. As I mentioned in silver, they don’t really add any new information - they make it easier and faster to consume the data. Often, information gets lost because of the fixed grain of the mart tables and OLAP cubes, resulting in a huge amount of work to extend and maintain them. This way of thinking is really a hangover from the old pre-Big Data era, where physical resources for the data warehouse were badly constrained.
Concepts like the USS belong in gold or can be dynamically built in the semantic layer, too.
I think the semantic layer can replace the gold layer entirely, with huge benefits in time, cost savings and consistency in data use from doing so.
It is right that the Medallion architecture naming isn’t the best - again, you can see why it appeals more to product marketing than data folks. It makes it easy to explain to consumers and stakeholders what they should be using, but is necessarily a bit childish. It’s like explaining how an economy works with lemons and lemonade stalls. It’s directionally correct, but not precise.
I would prefer naming like staging, model and presentation. This is much closer to what people already know and expresses what actually happens in the layers. Bronze, silver and gold make it easier to explain to non-technical users. That’s the only reason why the product marketers have gone for Medallion architecture, although whether non-technical users really need to understand “how the sausage is made” is another question.2
Or, a better method like some kind of incrementing version, but it’s common to use inequality joins as far as I have seen. Better methods for SCDs hugely depend on good data modeling in source systems.
Perhaps these non-technical buyers are non-technical from a data point of view, like CTOs often are, but are still broadly technical buyers. They need to feel like they understand, in case another C-suite member asks, and being able to talk about gold/silver/bronze data could make it sound like they have things in hand.
Really helpful and well-written, David!