
Semantic Superiority - Part 5
LLMs, AI, the good stuff... everyone's talking about it

In last week’s post, I ended by talking about why semantic layers haven’t yet lived up to their potential and how BI vendors have progressed as far as a pivot table type interface for semantic layer use - but haven’t gone any further in terms of accessibility.

The LLM-phant in the room
It’s perhaps unfair of me to criticise BI vendors for stopping at a pivot table-style interface - some recent advances in technology have made it possible to do more with natural language than ever before. The idea that a machine could reliably interpret natural language was science-fiction this time last year, not so this year.
Just like humans are on the verge of expecting to be able to ask a question and get good answers from a machine that has access to the majority of human knowledge, they will also soon expect to be able to ask a question and get an answer that’s based on data.
They won’t accept being forced to know where to look, or to have to precisely know the name of objects in a semantic layer.
They won’t accept being forced to leave their normal workspace to another application, where they have to use a complex and confusing interface to get what they need.
They won’t accept being forced to speak or write in a syntax that suits a machine.
They’re expecting to be able to talk to “Computer”, like in the world of Gene Roddenberry. Clearly and evidently, I believe applications powered by LLMs (LLMa) are the future interaction point for semantic layers.
In fact, I believe, people will rightfully regress. Even those who feel somewhat to highly competent using the BI tools of today will expect to not have to use them tomorrow. It’s not their job to know how to use them, they didn’t want to be an analyst - they wanted their own analyst on demand. On evenings, on weekends, at 3am, after the Christmas party, on public holidays… as and when they needed them. It was just too expensive to have that capability before.
To LLM or not to LLM
So where should LLMs interface with semantic layers? Should LLMs even generate semantic layers? It depends.
Dev Tooling
I think if you were to use LLMs in a CodeGPT/Copilot type way, where a human engineer reviews code before merge and deployment, then this is obviously the future as it is with many other spaces in engineering. There is a fair amount of boilerplate code in defining a semantic layer and using an LLM in the development process makes sense.
The LLM could even help you find relationships and possible metrics from a dbt project or database schema. After all, comparing the names, types, cardinality and sample data of columns with each other is something an LLM could do in a few seconds. This kind of exploratory data analysis has often taken human analysts and data scientists hours or even days to do.
With the metadata available from a dbt project (just dbt-core, not thinking about the semantic layer), most, if not all, relationships in a dataset are already explicitly exposed, as are many metrics. Each time you join tables in a dbt model, the join keys define the relationship. Each time you define a unique key on a dbt model, you define a possible entity. Each time you aggregate fields from previous models, you define possible metrics. An LLM parsing this metadata and creating the first commit and PR for a semantic layer is certainly possible. I wouldn’t rely on it without human supervision, but it would accelerate development hugely.
Semantic Accountability
If you were to allow an LLMa to generate the semantic layer without human supervision, for widespread use, I think you would be on the wrong path. LLMs aren’t accountable, and it’s possible only humans will ever be. Every activity in a business has a human that is accountable: the A in RACI1. This isn’t always explicit, but it’s always true. Even for ML use cases that have been around for a long time, like credit risk, there is always a set of humans who are accountable for the model.

When stakeholders and data users use data, they don’t necessarily care about how the data work to deliver it was executed, but they always expect there to be someone who is accountable for it. Typically, this is a Head of/VP of Data-type person and their team. When the data is being used, it is expected that a human can understand how the data is being processed throughout its provenance, including ELT and semantic definition.
Imagine a situation where a data user asked whether a data asset or answer given with data was correct, but instead of having a data team/person to rely on, they are just asked to trust that an automated system is correct. It just won’t fly. What will happen is that humans will be brought in to try and decompose what the automated system has done and humans are then pitted against the machine. As anyone in engineering knows, unreliable and unexplainable systems are soon replaced or deprecated.
Even if an LLM could be guaranteed to do a perfect job of defining the semantic layer, there is a good chance it still wouldn’t be acceptable. In Data, stakeholders expect to understand how meaning was derived (eg a customer is a user who has had an order where the order was not fully returned). A black box is not acceptable. The humans who are accountable for the data would need to be able to explain how the information presented to users was derived from data.
Applications which use an LLM to directly interface with a data store, at the very least, generate a minimal (implicit) semantic layer and possibly some transformation too, on the fly, upon each query. This means that a probabilistic process is defining meaning in your data for each query! As humans created the data structures and their meaning in the first place, why introduce a probabilistic element into the meaning of your data?
This direct interface approach usually involves generating SQL, but the same would apply to generating R, Python, Julia etc. If a data user had questions about whether the answer provided by the application was correct, they wouldn’t just tolerate being told that they would need to trust the application or that it would be wrong some % of the time. In reality, they would ask a human data person to come in and explain what was going on, and they would rightly say: “No thanks, I’ll just make you something myself”. It’s much easier to rewrite code than debug existing code, especially when it’s compartmentalised in the way that a single query is.
Whilst humans run organisations2, other humans will need to be accountable for semantic layers.
Interfaces with Semantic Layers
I’m increasingly becoming convinced that the entire modern data stack is on the cusp of getting rebuilt for our AI overlords. If that happens, data models won’t get built for people, but for LLMs. LLMs, however, probably won’t write pure SQL, which is riddled with complexity; instead, I’d expect them to run through semantic models like LookML. People ask the LLM a question; it creates a “semantic query;” a semantic layer complies that request into a SQL query.3 - Benn Stancil
LLM applications translating human questions into semantic layer API requests (SLAPIR) is much, much safer than having LLMs generate code that effectively generates the semantic layer when querying.
Why?
The LLMa doesn’t get to define what the data means, it only gets to find things that already exist that fit the question.
It’s easy and quick to get a human to validate a SLAPIR. It’s very limited in possible structure and content. Chances are, the human validating the request is the human that defined the semantic layer.
As the SLAPIR is so limited in structure compared to SQL or a language like Python or R, it’s much less likely that the LLMa would generate something wrong.
If the LLMa can’t find anything in the semantic layer that is similar to the question, it can decline to answer the question. Without this boundary, it will just guess and hallucinate. Data teams regularly tell stakeholders that what they asked for doesn’t exist or doesn’t have safe data to serve with.
The LLMa doesn’t get to transform data, SLAPIRs don’t allow you to do this.
If the SLAPIR has been validated and is good, then any issues with the output is automatically upstream in ELT. This makes it easier to pinpoint problems.

I disagree with Ankur, even if he is verified 😉. For the reasons I’ve described above, this isn’t a pure technical problem where the solution is a better-trained model on a vast high-quality training set. Trust, transparency and accountability are very important factors - they are more important factors, in my opinion.
Regarding the initial quote from Benn - I don’t believe there is a difference between a semantic layer being useful for humans and being useful for an LLM: the fundamentals of minimalism, clear naming, avoiding duplicates etc are all helpful for both.
Standalone semantic layers are the best for use with an LLM - they don’t require arbitrary compartmentalisation of your semantic layer into “explores” or “workbooks”, leading to possible duplicate entities, metrics and dimensions.
Another LLM interaction with a semantic layer that could be really great is explanation. Imagine being able to input a semantic layer definition file or repository and a question about it to an LLM, and then getting an answer based on an interpretation of it. For example, someone could ask: “How is a customer defined?” and they could get a response like: “A user who has had at least one order where the order was not fully returned”. This could make the semantic layer itself transparent to non-technical users.
On another note, I do believe LLMs spell the end of manual documentation and cataloging work. Relying on humans to maintain this manually, when they have time (which is never), has always failed. It’s relatively low risk, high effort content creation - perfect for LLMs.
SynthAI
Zeya Yang and Kristina Shen, of Andreessen Horowitz, recently published a fantastic article in relation to B2B applications built with LLMs.
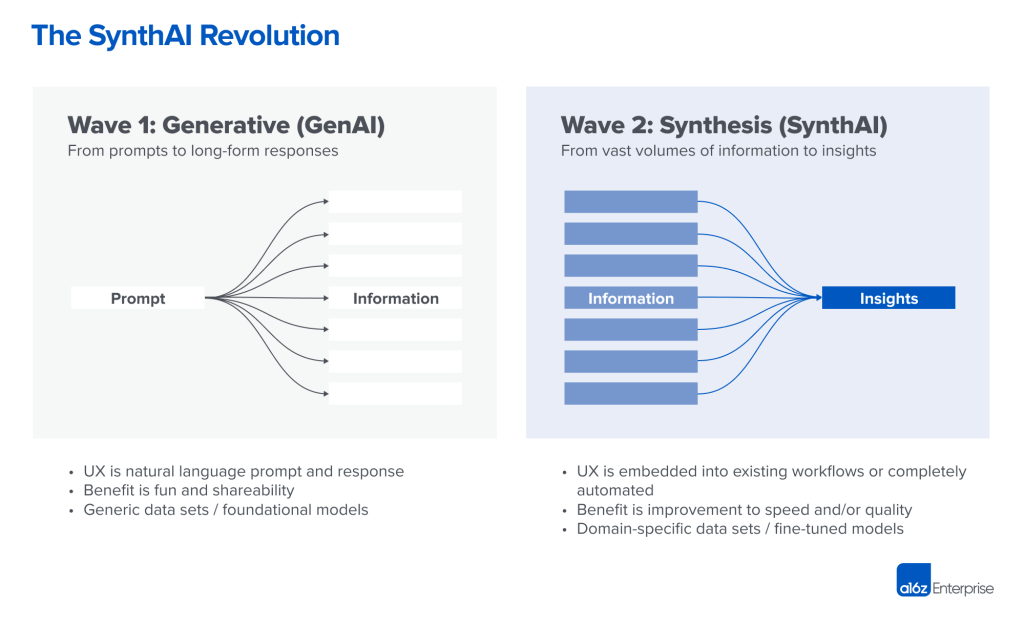
They describe two eras of AI products:
Where we mostly are now, including the approach above, which generates SQL or code from text for analytics - GenAI. These products help create a lot of information or content with relative ease.
A following era, which synthesises a large amount of information to generate fewer more relevant insights, either increasing speed whilst maintaining quality or increasing quality whilst maintaining speed.
LLM applications leveraging semantic layers are examples of SynthAI. The semantic layer used with with associated data generates information, this is its purpose. The extra metadata about its use and social context from API usage makes it an even richer source of information. Leveraging them is inherently domain-specific - it’s where domains are defined.
This is not my first set of posts on semantic layers, and I’m sure I’ll write about them again. I really want to explore the concept of metric trees in this context too, in a future post. Thanks for sticking with me to the end of this series! 😅
I’m hosting London Analytics Meetup #3 with Liron Albag of Depop at their head office in Farringdon, there are still some spots left so come join us!
https://en.wikipedia.org/wiki/Responsibility_assignment_matrix - although, in theory, a model could have delegated responsibility for executing a task.
It is conceivable that you could have a cookie cutter business run by AI, with human investors. Here, where business decisions using data are not being made by humans, it doesn’t matter that there is no human accountable for the semantic layer or that it’s only correct part of the time.
Really interesting!
Not sure I agree with this though.
> On another note, I do believe LLMs spell the end of manual documentation and cataloging work. Relying on humans to maintain this manually, when they have time (which is never), has always failed. It’s relatively low risk, high effort content creation - perfect for LLMs.
If you're expecting to use the semantic layer as the "thing" to ask questions from, then I think that clear documentation is incredibly important. For example, at Lightdash "what does activated mean" is really different to Monzo. We have an event `activated` but that's triggered by a backend event in a very specific situation (e.g. they have verified their email account at Lightdash vs. they have made their first transaction at Monzo). The LLM doesn't know this, because it doesn't have access to this context.
Right now, the incentives for writing docs are so low that no one does it - it's really unclear which models/metrics/dimensions I should be using in the first place as a business user, so I don't even get around to reading the docs! But, if an LLM is now effectively answering the majority of data questions for your business users, then suddenly the data team has a really important task of basically building + maintaining a dataset to train an ML model on (your semantic layer + docs). So, you're going to want to make sure that the training set is as good as possible so that the ML model is as effective as possible at answering those questions.
Context is key for data questions! Either as a semantic layer, or as docs describing that semantic layer. Agreed that MOST of the docs can be written by LLMs, but they'll definitely still need human input :)