

Last Friday, I looked at all of the kinds of model that sqlmesh has, except for the incremental types. They are the most complex, and are actually what initialising from dlt, using sqlmesh, generates.
sqlmesh model kinds - 1

Yesterday, I got my advent project to a point where I had ingested data from the Bluesky API endpoints for followers and follows using dlt. Then, I used the integration between dlt and sqlmesh to automatically generate sqlmesh models from tables created by the dlt pipeline in DuckDB:
There are three kinds of incremental model in sqlmesh:
Incremental by Partition
I’m starting with this one, as it’s probably the least commonly used and I won’t look to apply it in my project. It’s designed to be used with data warehouses that have explicit partition keys for a table, like BigQuery and Databricks. I say ‘explicit’ to mean that the data warehouse will actually store your data in exactly this way. Snowflake, for example, has a cluster by key to deliver a similar benefit to partitioning in other warehouses, but it does not change how data is stored in Snowflake micro-partitions, only how the data is sorted within these so that query pruning can be more effective.
The idea is that, when your increment runs and you get new data, it will completely remove any partitions which exist in the old data so they can be replaced by the new data, and only old partitions which don’t exist at all in the new data will remain. For data warehouses that do support this explicit partitioning, this should be an efficient way to run an incremental model. Old partitions are deleted where new exist in the increment and then all the partitions from the increment are inserted - there is no reason to scan or join old and new data in order to execute the transaction, it’s not merging anything.

A practical example could be where you are storing marketing performance data for cost per click. You might partition by a compound key of campaign and keyword, for example. If the model ran every day on the previous day’s data, the permutations of campaign and keyword that had activity on the previous day would have data and this data would replace the old, but if there was no activity, then there would be no data to replace it with and so it would remain. This, then, would keep the freshest performance data per compound key in the model.
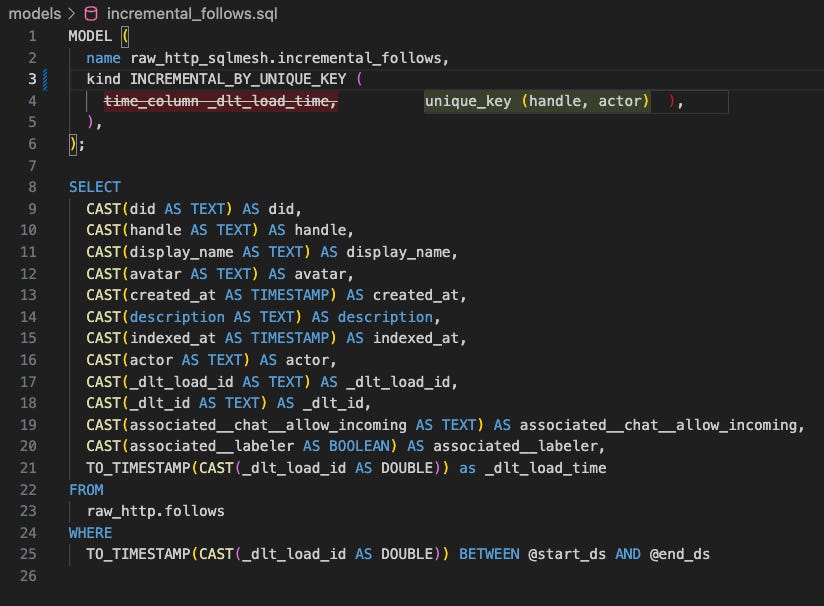
Incremental by Unique Key
This kind of incremental model is similar to the dbt incremental materialisation, where a unique_key is set. Many of you will be very familiar with this kind of model, where you are maintaining a dataset which has a primary key, most likely from a source system like an OLTP database or an event stream, and you are updating the records of the table in response to regularly arriving new data - whether this arrives in a streaming or batch fashion.

For example, with my Bluesky followers dataset, the appropriate unique key for this kind of model would be a composite key of (handle, actor), where the actor is the account being followed and the handle is the account following the actor. Many actors may have the same follower, so handle itself is not meant to be unique, and one actor will have one record per follower, so actor, too, won’t be unique - but the combination of actor and follower (handle) should be unique.
In fact, this is the most appropriate model kind for my followers and follows models, so let’s make that change.
Incremental by Time Range
This kind of incremental model is designed to deal with a data source like an event stream, where the incoming data is immutable.
I have seen this a few times before and one example was where I was using Snowpipe to ingest streaming data into raw event tables in Snowflake - Snowpipe would generate an insert_timestamp for when it ran the insert and every event ingested would also have its own event_timestamp related to when the event actually occurred. I would then use incremental models to take the new data based on insert_timestamp and process it.
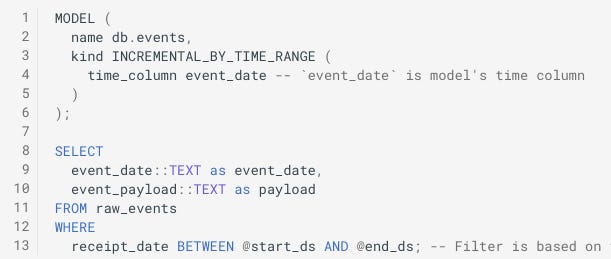
However, this is where there is a significant departure to the dbt incremental materialisation, which is really an append only model. As you can see above, there is a time_column parameter - this column which represents the time for each row and is used to filter the data output by the model, and also to select what part of the model to delete on each run. This is distinct from using @start_ds and @end_ds macro variables in the where clause, to filter the data read into the model from the source.

It is also expected to specify a @cron parameter, which states how often the model should run, but also is used to derive the time interval unit by default. The time interval unit can also be defined separately, if needed. By default, models won’t be executed for partial intervals, so the pink incomplete interval on the top diagram above wouldn’t run until the first run after midnight. You can override this with the allow_partials parameter, where it’s ok to have partial intervals (think product analytics vs revenue reporting).
Ah, what about late arriving data, you say? In the situation where I was using Snowpipe above, some of the events were generated by user’s browsers and when this is true, almost anything can happen because of caching etc. We would sometimes see event_timestamps come through one year afterwards! However, most of the time the vast majority of event_timestamps arriving in data for the day were related to the last two weeks’ activity. So, we implemented our own logic to handle this lookback period in our dbt models. sqlmesh has a native parameter for lookback periods, called lookback. It is an integer and refers to the time interval unit of the model, usually derived from the @cron parameter - it extends the time range specified by @start_ds and @end_ds backwards to match this. So, for a daily run model, a lookback of 14 would go back two weeks.
There is a great worked example of a more complex incremental by time model here, with a video walkthrough.
I’ve only covered a small number of the possible ways you can configure incremental models in sqlmesh - there are many other things you can configure, as you can see here. All of this makes sqlmesh more powerful than dbt for incremental models out of the box, but also more complex. However, as someone who has run dbt at scale and as part of a larger team, complexity then comes elsewhere. You end up adjusting how in-built macros work, hacking your own lookback methods… the SQL or jinja you write in your models becomes more complex to compensate.
Having more standard config available is more to learn and get your head round as you can see 👆 but it also means that, when collaborating at scale, what models actually do is more obvious to others. The lack of jinja is also refreshing and makes the model easier to read and less brittle - eg the where clause will always be in place (no need for 1=1) but it will just run with larger or smaller time intervals.
sqlmesh also saves state about your model runs, unlike dbt, which runs queries ahead of model runs to collect state from the models themselves. It saves this state either in your data warehouse (where possible - for some query engines this doesn’t work, only works single player, or is ill-advised/expensive), or in an elected database from a list of supported ones, in the database of your scheduler or in Tobiko Cloud.
Storing this state about your models separately means it can store things which aren’t easily apparent from the models themselves. Two core things stored are about model runs and time intervals. sqlmesh stores which time intervals have been run for any version of a model. Therefore, when incremental model runs happen, only fresh or lookback data is processed, leaving the rest of the data alone and saving cost. This includes where data is missing in the middle time intervals of a model. dbt incremental models can’t handle this situation - you have to full-refresh your model to fix or edit the compiled SQL, to cover the missing dates and run it manually1.
Storing this state in an appropriate database, hosting and managing this database2 and making it available for all engineers working on the sqlmesh project is a valuable service. This is a service that Tobiko Cloud can offer that dbt Cloud can’t, because it doesn’t store project state.
I’ll run my models tomorrow and show the state data stored in DuckDB, as well as talking about environments and snapshots in sqlmesh.
This is not much fun and is easy to mess up - you also have to handle the full transaction, with merge or delete/insert, which dbt compile doesn’t actually generate.
As soon as running a piece of infra involves standing up and maintaining a database, it’s a good breakpoint to have a build/host or buy decision. It’s NEVER trivial to look after a database. If the data it contains isn’t sensitive and doesn’t serve a core competency of the company… perhaps you shouldn’t look after it, especially if paying for a service is cheap.
If Tobiko Cloud’s state management feature costs anything like having a small RDS Postgres instance running, then the pricing is good. By the looks of things, even the tiniest instance costs over $500 a year and having even a modest instance quickly ramps up to over $3k a year. While sqlmesh state data isn’t sensitive, it could trigger a lot of inconvenience and expense if lost.