
Jevons Inversion
The paradox eats itself

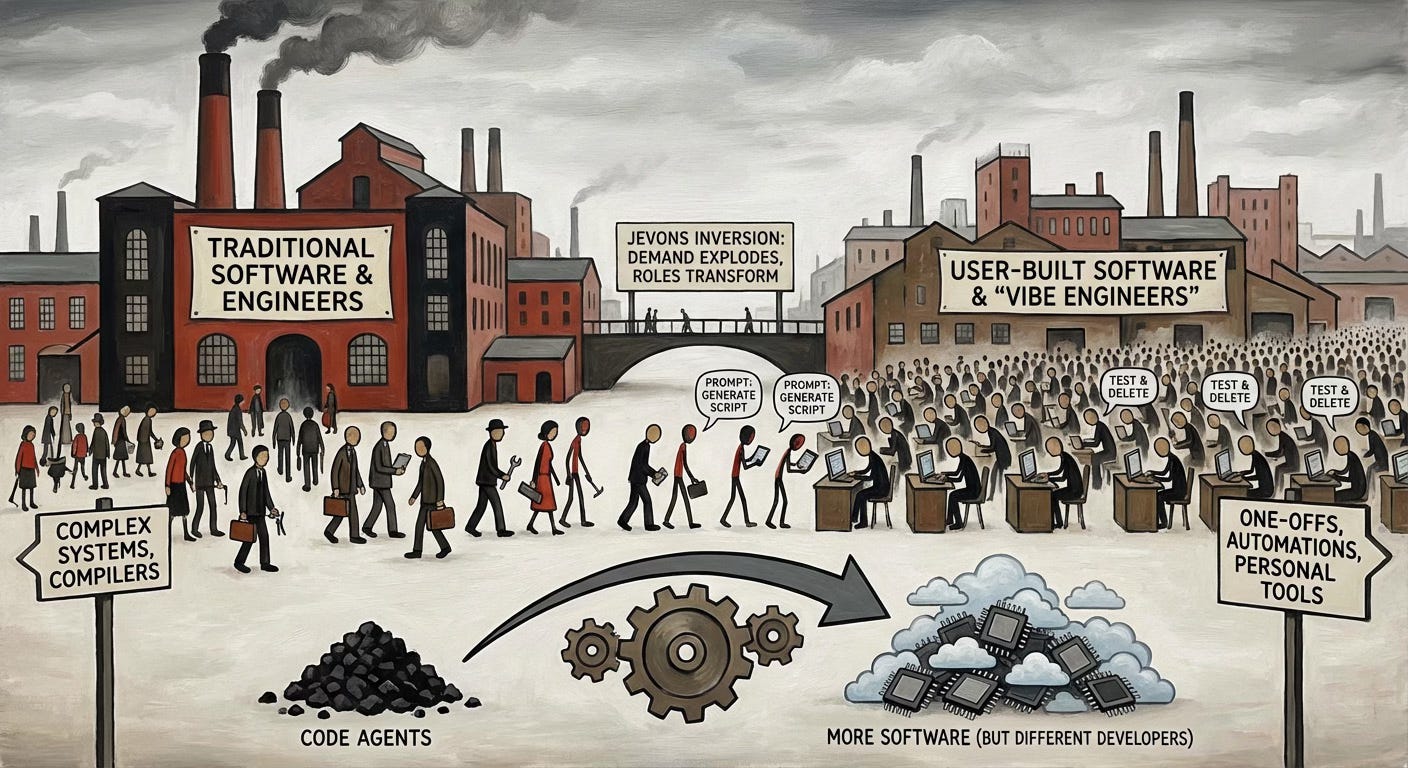
Simon Willison’s 2026 prediction for LLMs raised something that’s been rattling around my head. He invokes Jevons Paradox—the observation that as something becomes more efficient to produce, we don’t use less of it, we use vastly more. Coal. Compute. Now software.

The optimistic case for software engineers is roughly this: coding agents make software cheaper to produce, therefore we’ll want more software, therefore we’ll need more engineers. Jevons saves the profession. I’m not sure that it plays out this cleanly. Marc Andreessen published a post a couple of years ago suggesting this is how things would work more broadly, and I don’t think this is what we’ve seen.

The paradox, as typically applied, assumes the same people do the work. When coal extraction became efficient, you still needed miners. When compute became cheap, you still needed programmers. But what happens when the efficiency gain comes from mostly removing the need for the specialist? I think we may be about to find out.
There are many software engineers out there who aren’t working on particularly deep technical projects. They aren’t building compilers or high-performance computing systems or databases. They’re application developers, doing fairly similar things at company after company—1the somethingify pattern, the somethingly pattern. The advent of coding agents, from Lovable through to Claude Code, creates a spectrum of tools that turns anyone slightly technically able into something like a software engineer. Anyone who can use Excel competently understands data, logic, conditionals. They can’t write Python, but they can describe what they want, test whether it works, and iterate until it does.
Not good software engineers by 2022 standards, but good enough for what they need. People already used to operate like this… everyone had their trick spreadsheet that had a macro to automate something annoying for them. In a way we’re just expanding this concept.
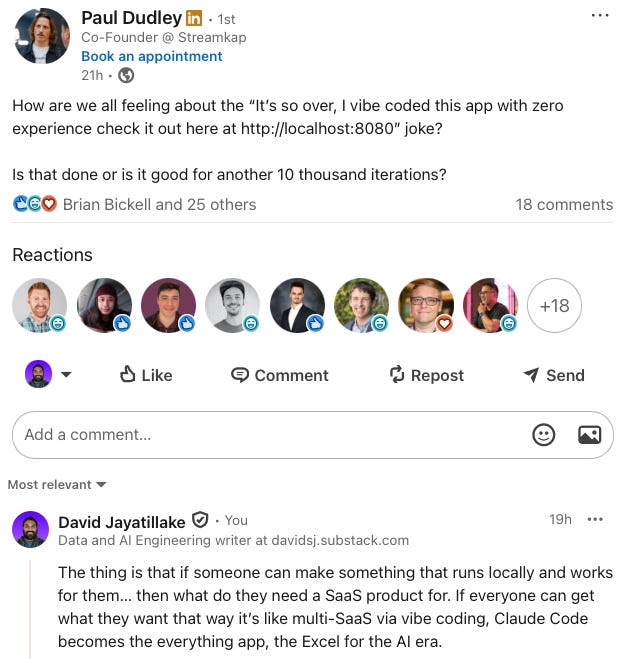
The most interesting shift to me isn’t what we build, it’s what we throw away. Consider software that runs once. You need to transform some data, validate something against a ruleset, generate a report in a specific format. Previously, you’d either do it manually which is tedious and error-prone or ask engineering, which means backlog prioritisation and weeks of delay. Now you describe it to an agent, it generates the code, you run it, you let it decay in the background of your desktop. This took seven minutes and would have taken two hours manually. Nobody calls this software development, but that’s exactly what it is.
And here’s where it gets interesting: agentic systems have memory. That single-use script you made last Tuesday? The next time you need something similar, the agent knows. Faster, more reliable, each iteration costing less until each use is a low effort one shot. Eventually, generating the code approaches the cost of running something deterministic. At that point, the distinction between “writing software” and “using software” starts to blur in ways I don’t think we’ve fully appreciated.
There’s also something worth considering about the overhead that disappears when users build their own software. Enterprise SaaS carries enormous costs because it has to. It serves thousands of users, so it must scale. It handles sensitive data across organisational boundaries, so security is key. It runs on someone else’s infrastructure, so efficiency matters. It must be sold, which means documentation, support, maintenance, and all the apparatus of a product company.
User-built software has none of this. It runs on your machine, so scalability is irrelevant… there’s one user. You already have access to the data, so security is just your existing boundary. Your laptop sits idle most of the day anyway, so efficiency barely matters. Documentation? You prompted it, so you understand it. All the boilerplate essentials that make SaaS saleable are unnecessary. The software doesn’t need to be good by any conventional standard. It just needs to work for you.2
So what does this mean for demand? I think Jevons Paradox will apply in aggregate. We will have far more software engineering done than ever before. But the composition of who does it may invert in ways that aren’t great for traditional engineers.
The world gains millions of what we might call vibe engineers; people who couldn’t write a function by hand but can orchestrate agents effectively. They’ll handle the long tail of software that was never worth building before: internal tools, one-off automations, personal utilities, departmental solutions that would never have made it through a prioritisation meeting.
The world may lose demand for a specific kind of engineer: the application developer doing similar work at company after company. Those roles existed because building software required the skill. When the skill is substantially automated, the role follows. What remains is complex systems where correctness matters: compilers, databases, security-critical infrastructure, frameworks that the agents themselves rely on. High-performance computing where efficiency isn’t optional. These need engineers who understand what they’re building, not just how to describe it.3
But that’s a smaller number of people than work as software engineers today. We’ll have more software engineering than ever. We’ll have more software engineers than ever. They just won’t be the same engineers, and most of them won’t think of themselves as engineers at all.
Jevons Paradox applies. The demand for software engineering explodes. The demand for software engineers, as we’ve known them, may not.
Happy New Year! 🎉
I endorse the use of em dashes, they are efficient! Which is probably why LLMs use them so much.
There are caveats around inadvertent security breaches from LLMs writing unsafe code and having access to sensitive data or systems, but coding agents continually improve in this regard and as Simon also predicted: we will solve sandboxing soon to prevent this being such an issue. I think it could be as is simple as a company like Anthropic buying a Fly.io or equivalent.
Most of the time a user does not want to send data externally, most of the time they want to consume data and manipulate it locally. Sandboxes can be configured to block directions of network traffic that are unneeded and unwanted. Users who do want to send files or data onwards as part of a workflow they are building or automating, often want these to flow to an internal recipient or approved system. There is much less risk from sending some unexpected data to your company Salesforce, than a random external server.
I experimented with converting DuckDB to Rust over Christmas, just to see how capable best in class coding agents like Claude Code with Opus 4.5 are, it managed to do the conversion but most of the tests are still failing. This is even just a translation of a complex codebase from one language to another. I think we are some way from a coding agent being able to build something as complicated as a database without highly skilled specialist software engineers.
I have a very hard time believing that LLMs will code something fundamental like `yacc` more efficiently than the craftsmen who first put it together. I think we'll have the software equivalent of vast, soulless and marginally efficient glass & steel towers. Sure the Lever Building was a marvel, but eventually people will want pre-war architecture.