
Package Deliverator
Does the future of Analytics Engineering involve writing less SQL?


As I’ve mentioned in the post below, I’m starting a new dbt project at Metaplane, to cover our analytics needs.
It’s public, so feel free to take a look. We also have github pages for our dbt docs.

So far, I’ve written no SQL at all, but I’ve got to over 180 models. I’ve done all of this through using dbt packages. All data flowing into our DWH either streams in from Segment (also soon via CDC on our RDS Postgres db) or from Fivetran connectors.
Fivetran
I remember visiting Fivetran’s fairly humble booth at Snowflake Summit 2019 in London. At the time, they were seen as a small disruptor in a space dominated by established players like Informatica. They became a unicorn a year later, and have gone from strength to strength, becoming by far the dominant no code EL (extract and load) platform. Their valuation is much higher than all competitors, save Informatica who have a similar valuation; Informatica have much higher revenues than Fivetran, but lower growth, reflected in the revenue multiple.
I remember having a demo of Informatica in 2018 and I was disappointed by how clunky and antiquated their UI was; it looked so complicated to use. It made me think it would be easier to use open-source or homemade solutions. It was also incredibly expensive, even at a base platform cost level. Having recently used Fivetran for the first time at Metaplane, I felt completely differently. Fivetran has a clean, simple UI and getting data moved from source to DWH is as straightforward as providing credentials for both in a guided process. It would be easy for anyone to use, even those who aren’t that familiar with Data Engineering processes.
Fivetran is also affordable to start with, as there are no base platform costs, purely consumption costs. I imagine at a large org that moves lots of data, that this could become expensive, as has been mentioned in the data community. However, at the same time, you’re paying a lot to get a lot done and I imagine there is possible price negotiation at this scale. It will always be cheaper than hiring a team of Data Engineers to build something that is reliable and scalable. At the scale of data that Metaplane will have for the foreseeable future, Fivetran will remain very affordable, both in terms of consumption costs and engineering time saved.
When deciding which ELT provider to use, I wanted to maximise the empathy I could have with customer stacks. I chose Fivetran because it is by far the most used ELT provider by our customers.
Fivetran recently acquired HVR to add CDC (Change Data Capture on databases) streaming EL to their product offering. CDC ELT is seeing traction in investment in the last year, with the likes of Hevo, Striim, Arcion and new entrant Streamkap raising or entering the market. Fivetran’s acquisition of HVR is a validation of this market segment - with Fivetran, and similar era competitors, batch ELT feels solved and streaming is the new frontier.
If Fivetran acquired a company like Rudderstack or Snowplow, they would have the full gamut of common data ingestion patterns.
Airbyte recently bought Grouparoo in order to have reverse-ELT/data activation/operational analytics 😁 capabilities. I can imagine Fivetran not needing to acquire a company to provide these capabilities, as they have a huge number of engineers and are specialised in building connectors. Yes, taking data from the DWH and sending it to a target system is a different workflow to taking data from a source system and sending it to a DWH. However, I don’t believe it’s so different that engineers well-versed in building the latter type of connector couldn’t move to building the former - the focus is similar.
Packages
Fivetran have built a number of dbt packages to use with data from their connectors:

In fact, there are possibly more Fivetran dbt packages than all others combined.
It makes complete sense for Fivetran to provide these packages for use with their connectors:
A lot of Fivetran customers use dbt (as is evident with Metaplane customers)
Fivetran know the data their connectors output and their relations plus other properties better than anyone else - why should every Analytics Engineer have to figure this out each time?
This is a huge competitive advantage over other ELT vendors who don’t provide the same packages. Analytics Engineering teams who use data from the sources above will greatly benefit from Fivetran’s packages, in order to have end tables that are usable elsewhere from the get go.
It’s transparent - any Analytics Engineer can understand the logic used in the packages to create models.
It’s open-source - any Analytics Engineer can make a PR to fix bugs or add additional features to a package.
There are many companies who use Fivetran for 100% of their EL, so with these packages they get to have data that’s ready to be joined across sources very quickly - concentrating on business logic rather than cleaning and understanding their data. While we won’t use Fivetran for 100% of our EL, due to systems like Segment which we use for event tracking, we will use Fivetran for 100% of our batch EL. This is a key point, because batch EL dictates the cadence of transformation processes.
Transformations
Streaming data is always as up-to-date as it can be (perhaps with a small delay that for BI use cases doesn’t particularly matter). Therefore, when thinking about orchestration of your transformation processes, you should consider ensuring your batch connectors have run as recently as possible, so all of your data is fresh. Of course, if you take a software defined assets, just-in-time analytics or reverse orchestration approach, this isn’t a problem. However, this way of doing orchestration is a new paradigm and well-explored elsewhere.
Fivetran have recently introduced Transformations into their product offering, which involves kicking off a dbt job after one or more Fivetran connectors have run. This, in addition to providing the packages above, makes Fivetran a full EL and T platform, rather than just EL.
The Transformations product is also a basic orchestrator, as it ensures your Fivetran data connectors and transformations happen in the right order, at the right time. If all you have is streaming data and batch from Fivetran… this could be sufficient - certainly for an organisation with simple data requirements.
With dbt supporting Python on Snowflake, Databricks and GCP, it’s also possible to have more complex pipelines orchestrated by Fivetran Transformations, as they can be in your dbt job. If Fivetran were to acquire or build reverse-ETL capabilities that could then be scheduled after a Transformations node… they would have an end-to-end DAG capable of advanced processes. For example:
[Fivetran Hubspot connector, Fivetran Stripe connector] |>
Fivetran Transformation (dbt job, including churn prediction using Snowpark/Databricks or Continual) |>
Fivetran Hubspot connector (RETL churn predictions)
Then the loop begins again… a full data lifecycle.

The very simple DAG I created in Airflow could very easily live in this feature instead, so let’s give it a try.
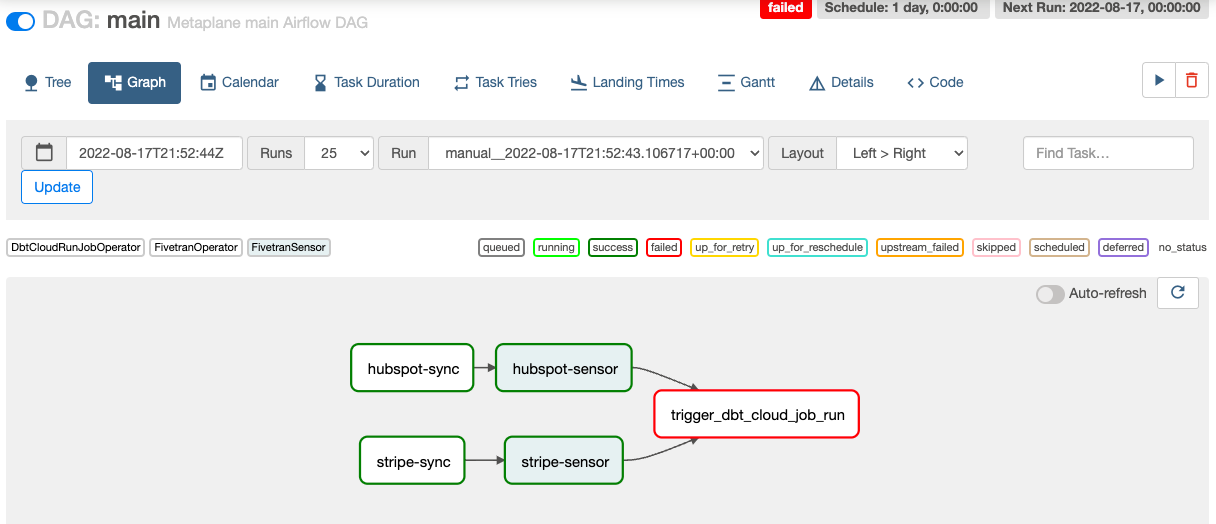
Fivetran’s implementation of how to orchestrate dbt transformations is very interesting (here are the docs for full details). With regard to how it works this is the key part:
You create a transformation in the Fivetran dashboard for each dbt model that you want Fivetran to run. Each transformation consists of the following elements:
Output model: A dbt model that transforms your data so it’s ready for analytics.
Output model lineage: All upstream models that are needed to produce the output model, starting from your source table references in dbt Core.
Schedule: A customizable schedule that determines how often Fivetran runs your transformation.
IMPORTANT: Each transformation references a single output model but executes all upstream models during each run.
By default, new transformations have the same schedule as their associated connectors, also known as a fully integrated schedule. Learn more in the fully integrated scheduling section.

I feel like fully integrated scheduling is a step towards some of the approaches focused on the data asset mentioned above. However it’s not the whole way there:
You do say which asset (model) you want to be updated.
Fivetran does figure out everything upstream that needs to happen before it.
But it’s orchestrated based on the schedule of the connectors which are the first tasks in the DAG.
There isn’t an SLA related to how often you want the asset in question refreshed by default, unless you choose to have it refreshed at a different cadence to your connector runs.
It would be nice to be able to choose multiple models per transformation rather than having to create one per model. For example as you can see with hubspot__companies and hubspot__engagements below, they share the same source connector and have big overlap in upstream models too. It does seem sensible to be able to include both of these in the same transformation to avoid re-running upstream models unnecessarily.


Logs
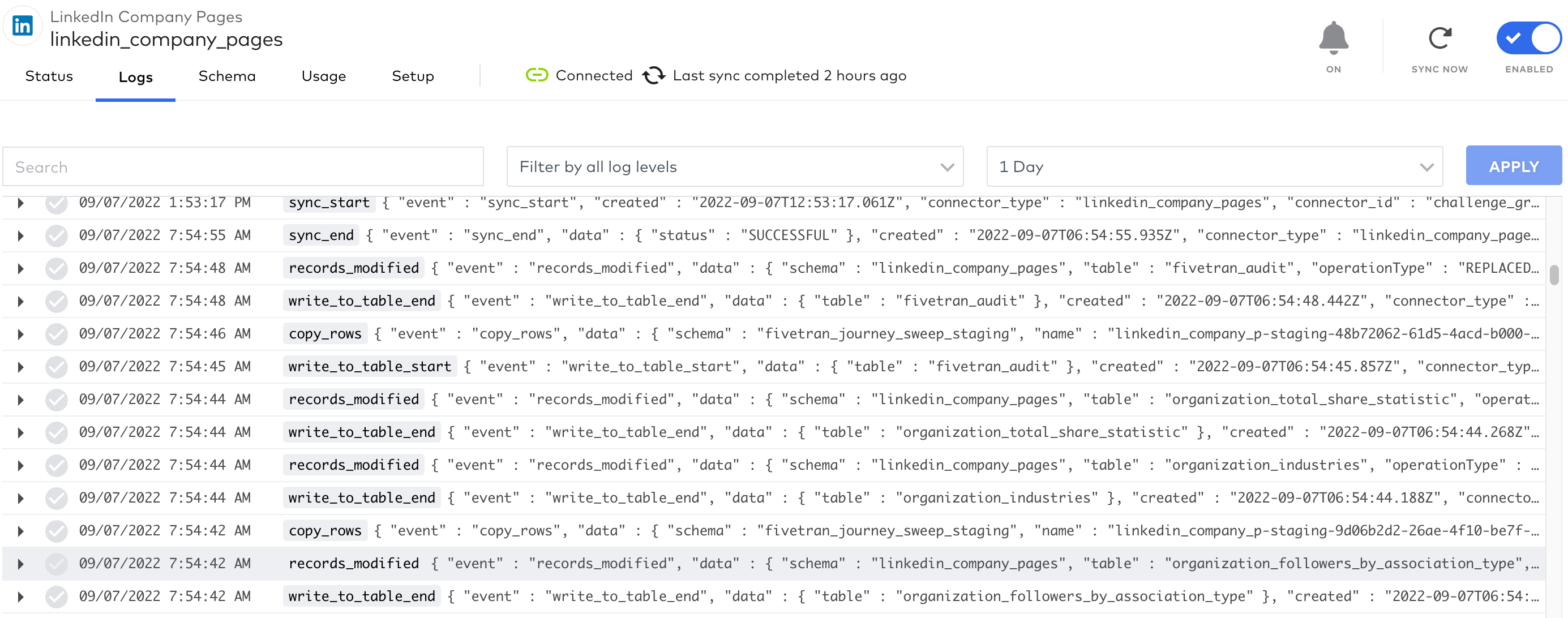
Looking at Fivetran logs, they seem to be a pretty rich source of metadata for a platform such as Metaplane to observe. With transformation logs also available, it makes the metadata that Fivetran holds even richer.