
The Modern Data Stack is Dead, Long Live the Modern Data Stack - Part 2
A Very Modern Data Stack 2024


Continuing from last week…
I wrote a post called a "A Very Modern Data Stack" early on in this Substack:
In this post, I shared a plan for data architecture that I intended to deploy:

A lot of the tools I chose in the diagram above were there to solve a specific technical use case I had identified. Some were already there and performant, as I far as I knew. A lot of the focus is on engineering, rather than on giving users ways to interact with data. It had decent scope for data teams to interact with their stakeholders, but less than I would want in the coming era.
Let's refresh it, and look forwards towards 2024:
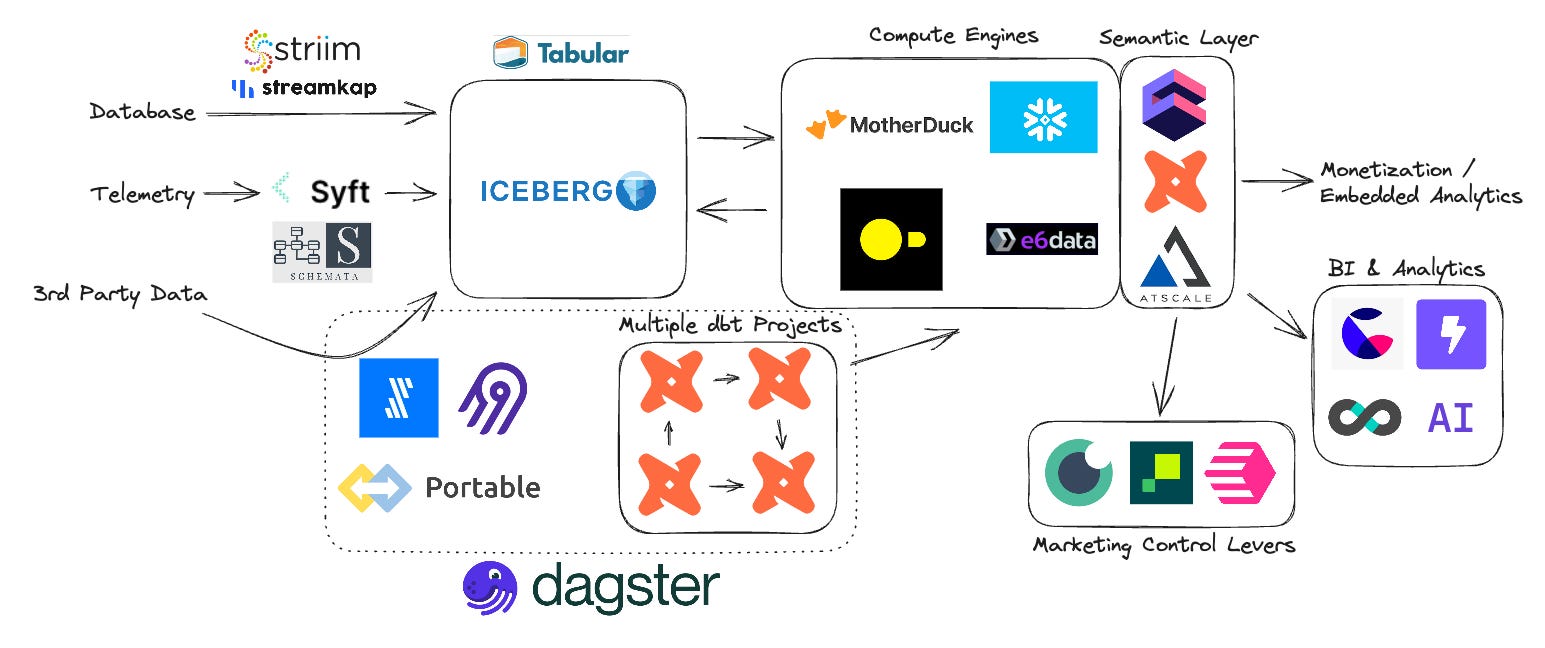
Ingest and Telemetry
People have said that 2023 is the year of streaming, and I think with CDC solutions like Streamkap1 and Striim available, plus enhancements from cloud vendor offerings, we will see data from internal databases become ingested using streaming.
Syft data is open-source and provides engineers with a way to implement telemetry with data contracts, by following good engineering practices. This improves data quality at the source, during development! It also provides a better way to interact with product engineers than getting them to use another system to agree data contracts. I’m really enjoying their new blog series, too.
Whilst Syft ensures that what was instrumented is complete, correct and stays so, Schemata helps you understand if you should or could have collected more data at this point to enhance connectivity between data domains. I can see Syft and Schemata being a powerful combination in the future. Recombining data that could have been sent together in the first place, is a major way that data teams end up wasting engineering time and compute cost.
Fivetran and Portable provide SaaS solutions for mainstream and long-tail data sources, respectively. Airbyte is open-source and I was surprised by how well-loved it is by data teams (I was at a dinner with some data leaders), for being open-source and free to use.
Orchestration
Dagster Cloud is much easier, more powerful and cheaper to use than a hosted version of Airflow. Hosting Airflow yourself is not free - it's "free like a puppy" (so not free). Dagster is also open-source. I’m not an investor, I’ve never worked there, I have no stake in it whatsoever, but every time I talk to people about orchestration, I say use Dagster - I’ve been doing Pedram’s new job for free!
Dagster also makes using multiple dbt projects together pretty painless. Software Defined Assets enables the ability to refresh end target assets: from source connectors, through multiple dbt projects, running only required nodes, if and only if they aren’t fresh enough which are needed to update the target asset.
Kestra, Mage and Prefect also look interesting in different ways - but for MDS teams, Dagster is the one.
Compute Engine
DuckDB, and companies offering hosted versions of it, will provide a much cheaper alternative to BigQuery, Snowflake or Databricks. Platforms like MotherDuck offer a “Hybrid Execution”, where data can be cached locally for performance and cost savings. However, if you do need the power of the cloud, it's there for you to use. Your local data can also be used in conjunction with remote data, to minimise remote data scanning.

The majority of companies in the world have data small enough to use locally with DuckDB. The vast majority of companies in the world have data small enough to use with MotherDuck. After all, many companies with small data simply use self-hosted Postgres or RDS Postgres as a data warehouse. DuckDB will massively outperform Postgres on the same resources for analytical workloads, and can horizontally scale with additional instances querying the same data, unlike with Postgres.
With Iceberg emerging as the standard of the data lake, it's also workable to use multiple query engines on the same data. Maybe MotherDuck would be sufficient for 99% of workloads and would enable snappy analytics performance with local caching, but you still want to use Snowflake for a workload that’s too big for the biggest EC2 instance.
E6data will provide a hugely faster and cheaper SaaS alternative to the big three, once it has the ability to cope with ELT workloads. Even so, as storage is shared between all compute, you can use something else to do ELT for now and enjoy the speed and high concurrency of E6 on huge query load - both vertical & horizontal.
The data warehouse is usually the largest cost in the Modern Data Stack. With the alternatives above, I see this reducing dramatically in the near future. The counterargument to this cost saving is that the three established data warehouses have made strong ecosystems. These are, yes, easier to spend on, but are also an easier way to deliver value.
If you save money on Snowflake, but spend a great deal of additional money and time engineering (which results in more cost), are you sure that you're saving money? If the data team is slow to deliver to save cost, there is opportunity cost in the stakeholder team. The point I make is that there is choice here that we didn't have before. If you wanted to stay a pure Snowflake house, you could remove Tabular and use managed Iceberg on Snowflake.
Consumption
On the consumption end, things have improved in a number of ways for data users. In the previous diagram, I had Hex and Lightdash2 as the two ways to consume data for users, with Rudderstack also sending data to a CRM.
As I've mentioned in this series before, and in what I'm doing as a founder, I think we and our stakeholders should expect more from self-serve, using AI and semantic layers.
Hex was a very good step away from a BI tool and towards something more free-form for analysts. This time around, I think Count is pushing analyst-served insight even further forward. Their canvas-style interface allows for real-time interaction between stakeholder and analyst. This enables very fast iteration time on work, and less time wasted by analysts feeling they need to get to a finished article before sharing. Analysts can get feedback as they go along, keeping them on an efficient path to solving their stakeholder's need. It does require a culture of trust between analyst and stakeholder, but that's where I want to be.
So, this shows three distinct ways to serve data to data users in an organisation:
Very rapid self-serve, using AI on the semantic layer, for simple to moderate queries.
A BI tool that allows exploration for skilled users and also houses standard reports. This tool should sit on the semantic layer, but not contain it.
A free-form tool for analysts to answer abstract or deep questions collaboratively with stakeholders. The analysts are empowered to work more in this space by the self-serve elements of the last two options.
It would be good for the last option to also have the semantic layer as an entry point for generating data sets. Count has recently begun to support references to dbt models, but also pushback of cells to dbt models. Hex supports dbt metrics already, and is committed to supporting the new version on launch.
These three options, sitting on a standalone semantic layer, will altogether be much cheaper and more powerful than a traditional all-in-one BI tool.
Semantic Layers
For companies who have a way to monetise their data with customers, in addition to internal use cases, Cube's semantic layer becomes a strong choice. Cube allows for metrics and dimensions to be defined in dbt format, or their own modelling language which closely resembles LookML. It also has SQL, REST and GraphQL APIs, allowing support for a wide range of software engineering use cases, as well as BI. It is also the only fully open source semantic layer.
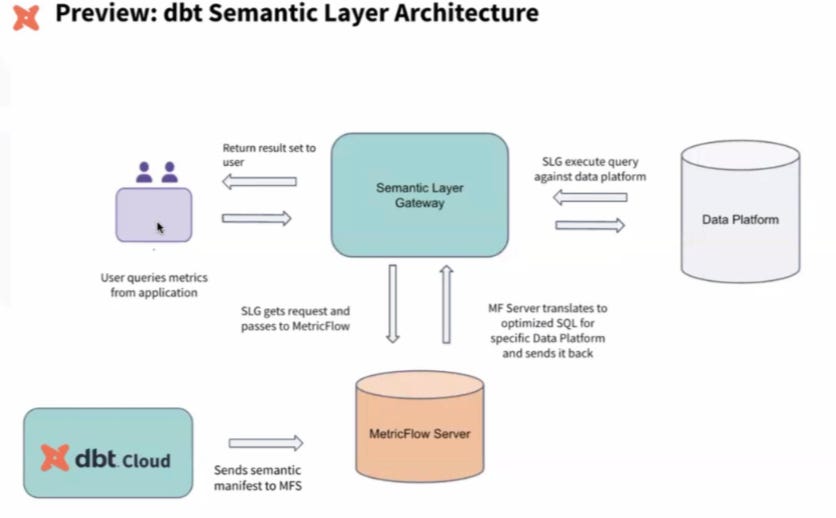
I’m also looking forward to learning more about dbt’s next generation semantic layer, based on MetricFlow, over the next few months. Here’s a small screenshot of the architecture from a recent dbt office hours session.
AtScale has been serving large enterprise as a standalone semantic layer for some time. Perhaps the market penetration of semantic layers is relatively low, but with the size of AtScale’s customers - an incommensurately large amount of data is served via a semantic layer.
Reverse ETL, or how we connect data with marketing activity
Finally, reverse ETL tools allow for complex segmentations, not possible on the fly in an event stream, to be sent to CRMs and paid marketing platforms. So, this is an addition to the stack, but it will directly drive revenue with your marketing team. Hightouch and Census are strong options here. Hightouch has doubled down on making things easier for customers with marketing use cases by offering automated identity resolution! I believe Hightouch will become a viable replacement for a CRM soon, which is why I haven’t put one on the diagram. I feel the end destination for Reverse ETL tools is to be the only place data needs to go to control marketing levers, batch or streaming. Where one tool goes, the others must follow…
It’s also good to see a new open-source tool in this category, in Valmi.
Off the DAG
For simplicity, I've not included metadata tools which look at the stack from the outside-in, like Metaplane3, Monte Carlo, Synq, Select Star, Alvin, Castor, Secoda and Atlan. These tools can be very helpful, but aren't on the critical engineering path to value. They protect the value created or expose it more widely. If they were on the diagram, they would span across the stack. If you think about the diagram as a graph with nodes and edges, the observability and lineage tools are focused on the edges and the catalog tools are focused on the nodes.
In Summary
dbt-core is the only part that hasn't changed and isn’t optional - its use has become more nuanced, with other tools like Dagster changing how we use it.
The need for data storage and semantic layers to be independent parts of the stack has become clearer. This has also been achieved.
To summarise the progress: we've become more focused on value to the customer, whoever they are:
Non-technical internal stakeholders, who are not able or inclined to become "data literate"
Internal stakeholders who are capable with data
Internal stakeholders who need answers to abstract or deep questions, in collaboration with analysts
Marketing teams who need to react to real-time customer events
Marketing teams who need segments with complex definition
External stakeholders who need access to data products sold
We now have open-source tooling as options across the stack, too, so there are choices for teams that want to control cost in different ways. Each tool category has at least one open-source option - you can choose to run a whole MDS end-to-end on your own infrastructure if cost or security is a huge concern.
This is still the Modern Data Stack, but it's moved with the times. It's leaner, it's meaner, it's focused on the money.
I now have some content for “The Human Interfaces of Data” series, so expect the first post next week.
I am an investor
I am an investor
I am an investor
Fantastic read! Your exploration of the evolving data stack is both insightful and forward-thinking. I particularly resonate with your observation on the growing prominence of DuckDB as a viable, cost-effective alternative to traditional cloud data warehouses. As discussed in our Apache Parquet and dlt integration:
https://dlthub.com/docs/dlt-ecosystem/file-formats/parquet
our team has seen firsthand the benefits of utilizing columnar data storage formats like Parquet with systems such as DuckDB. This approach not only optimizes performance but also promotes efficient data management and querying. Keep up the great work! Your insights are invaluable as we all navigate the ever-changing landscape of data engineering.
Best,
Aman Gupta
DLT Team